文件上传是 Web 开发肯定会碰到的问题,而文件夹上传则更加难缠。网上关于文件夹上传的资料多集中在前端,缺少对于后端的关注,然后讲某个后端框架文件上传的文章又不会涉及文件夹。今天研究了一下这个问题,在此记录。
先说两个问题:
- 是否所有后端框架都支持文件夹上传?
- 是否所有浏览器都支持文件夹上传?
第一个问题:YES,第二个问题:NO
只要后端框架对于表单的支持是完整的,那么必然支持文件夹上传。至于浏览器,截至目前,只有 Chrome 支持。 Chrome 大法好!
不要期望文件上传这个功能的浏览器兼容性,这是做不到的。
好,假定我们的所有用户都用上了 Chrome,要怎么做才能成功上传一个文件夹呢?这里不用drop这种高大上的东西,就用最传统的<input>。用表单 submit 和 ajax 都可以做,先看 submit 方式。
<form method="POST" enctype=multipart/form-data>
<input type='file' name="file" webkitdirectory >
<button>upload</button>
</form>
我们只要添加上 webkitdirectory 这个属性,在选择的时候就可以选择一个文件夹了,如果不加,文件夹被选中的时候就是灰色的。不过貌似加上这个属性就没法选中文件了... enctype=multipart/form-data 也是必要的,解释参见这里
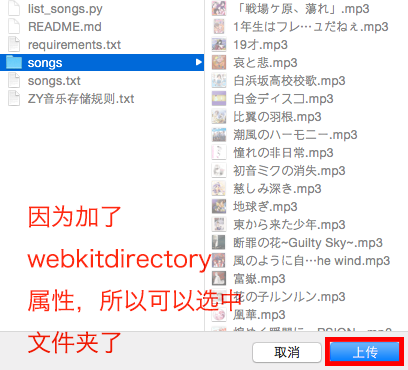
如果用 ajax 方式,我们可以省去<form>,只留下<input>就 OK。
<input type='file' webkitdirectory >
<button id="upload-btn" type="button">upload</button>
但是这样是不够的,关键在于 Js 的使用。
var files = [];
$(document).ready(function(){
$("input").change(function(){
files = this.files;
});
});
$("#upload-btn").click(function(){
var fd = new FormData();
for (var i = 0; i < files.length; i++) {
fd.append("file", files[i]);
}
$.ajax({
url: "/upload/",
method: "POST",
data: fd,
contentType: false,
processData: false,
cache: false,
success: function(data){
console.log(data);
}
});
});
用 ajax 方式,我们必须手动构造一个 FormData Object, 然后放在 data 里面提交到后端。 FormData 好像就只有一个 append 方法,第一个参数是 key,第二个参数是 value,用来构造表单数据。ajax请求中,通过 input 元素的 files 属性获取上传的文件。files属性不论加不加 webkitdirectory 都是存在的,用法也基本一样。不过当我们上传文件夹时,files 中会包含文件相对路径的信息,之后会看到。
用 ajax 上传的好处有两点,首先是异步,这样不会导致页面卡住,其次是能比较方便地实现上传进度条。关于上传进度条的实现可以参考这里。需要注意的是contentType和processData必须设置成false,参考了这里。
前端说完了,再说后端。这里以 flask 为例。
@app.route('/upload/', methods=['POST'])
def upload():
pprint(request.files.getlist("file"))
pprint(request.files.getlist("file")[2].filename)
return "upload success"
现在可以解释为什么说所有后端框架都支持文件夹上传了,因为在后端看来文件夹上传和选中多个文件上传并没有什么不同,而后者框架都会支持。flask 的 getlist 方法一般用来处理提交的表单中 value 是一个 Array 的情况(前端用name="key[]"这种技巧实现),这里用来处理多个上传的文件。
我们选择了一个这样的目录上传
car/
|
+--+-car.jpeg
| +-download.jpeg
|
+--car1/
|
+-SS.jpeg
pprint(request.files.getlist("file"))打出下面的结果:
[<FileStorage: u'car/car.jpeg' ('image/jpeg')>,
<FileStorage: u'car/download.jpeg' ('image/jpeg')>,
<FileStorage: u'car/car1/SS.jpeg' ('image/jpeg')>]
可以看到,相对路径被保留了下来。可以用filename属性获取相对路径,比如request.files.getlist("file")[2].filename的结果就是u'car/car1/SS.jpeg'。接下来,该怎么保存文件就怎么保存,这就是各个框架自己的事情了。
EDIT
查了一下,确实文件夹上传模式和文件上传模式是不兼容的,参见 这里,引用关键部分:
We only propagate a single file chooser mode which could be one of: { OPENFILE, OPENMULTIFILE, FOLDER, SAVEASFILE }. Only one mode can be selected and they cannot be or'ed or combined. Therefore there's no chance to enable both mode.
EDIT 2
文件上传的程序给师兄和自己用了几个月,单文件上传一直很稳定。今天试图传一个包含很多文件(2000+)的文件夹上去,遇到了问题——进度条能够走到最后,但是随后就看到浏览器控制台里报错 net::ERR_EMPTY_RESPONSE。看了下后端的输出,Flask 并没有接到请求。首先怀疑的是文件数量过多或者大小太大,查了下,浏览器有限制但似乎是 4G,我还远远没达到,所以不是这个原因。然后看有人提到 PHP 的 timeout,即一个请求如果持续太久后端就直接断掉它。不过 Flask 似乎也没有这种设置。偶然间看到这里提到 gunicorn 默认 timeout 是 30s,恍然大悟,原来是 gunicorn 导致的。
于是在 gunicorn 启动的时候加上 --timeout 120,这次是 500,总算有点进展,因为请求至少发到后端去了。看了 flask 的 log,错误原因是 too many open files,然后 ulimit 一下果然只有 1024。Flask 上传文件时,500KB 以下的直接以 StringIO Object 的形式存在内存中,大于 500KB 的用 tempfile 存在磁盘上。所以我传的文件一多,很容易开的文件描述符就超了。改 ulimit 也遇到一点小问题,最后按照这里说的用
sudo sh -c "ulimit -n 65535 && exec su $LOGNAME"
解决。之后再次上传就没有问题了。
参考资料:
1. http://stackoverflow.com/questions/4526273/what-does-enctype-multipart-form-data-mean
2. https://developer.mozilla.org/en-US/docs/Web/Guide/UsingFormDataObjects
3. http://www.w3schools.com/jsref/propfileuploadfiles.asp
4. https://github.com/kirsle/flask-multi-upload
5. http://stackoverflow.com/questions/9622901/how-to-upload-a-file-using-jquery-ajax-and-formdata
资料4的那个demo给了我巨大帮助,没它的代码估计我会多花几倍时间,虽然它实现的是文件上传而非文件夹,但其实没什么不同。
In this article, I'm going to talk about the combination usage of node-webkit and PeerJs, but first let's take a look at things we're going to talk about. Node-webkit is an app runtime that allows developers to use Web technologies (i.e. HTML5, CSS and JavaScript) to develop native apps. PeerJS wraps the browser's WebRTC implementation to provide a complete, configurable, and easy-to-use peer-to-peer connection API. If you haven't heard about them, I suggest you go to their websites and take a quick look at what they do, cause they both are really insteresting projects.
Why do I write this article?
There has been some discussions on running peerjs client in a node.js application, but apparently it's not easy to do this because PeerJs relies on WebRTC which is built into Webkit. Then, as node-webkit gets more and more popular, people start to think, why not use PeerJs in node-webkit so that we can build p2p apps? Here is an attempt, as you see it really works, basically it's the same as running PeerJs in browser.
Yet, simply using node-webkit as a browser and running PeerJs in it waste the most powerful feature node-webkit provides: the node.js runtime. Browser is cool, HTML5 give us the ability to cope with files stored in local computer, but those features are minor compared to what nodejs can do. If a node-webkit app don't make use of nodejs, why bother using node-webkit instead of writing a pure web app?
The node-webkit project I'm working on needs nodejs(db strorage, watching files, etc...) as well as PeerJs. First I tried something like this:
<!DOCTYPE html>
<html>
<head lang="en">
<script src="peer.js"></script>
</head>
<body>
<script>
var peer = new Peer('username', {key: 'my-key'});
var conn = peer.connect('hehe');
var fs = require('fs');
// sender side code
conn.on('open', function(){
console.log("connect to peer");
var data = fs.readFileSync('file-you-want-to-transfer');
conn.send(data);
console.log('data sent');
});
// receiver side code
peer.on('connection', function(conn) {
conn.on('data', function(data){
fs.writeFileSync('received_file', data);
console.log("received complete: ", Date());
});
});
</script>
</body>
</html>
It doesn't work because there's no node.js runtime in html, So you can't read from/write to local using fs.write/readFileSync. You probabaly know that node-webkit's node runtime can't really interact with DOM environmen——it lets you require a nodejs's script and call its function from DOM, but you CAN'T GET THE RETURN VALUE, the functon you invoked is run in node runtime and knows nothing about DOM, that's why the above code couldn't work.
Then my friend suggested me to run an express server on localhost and use socket.io to make node and DOM interact with each other. I've written a demo and put it on github to show how this works:
https://github.com/laike9m/peerjs-with-nodewebkit-tutorial
This demo could be run either on a single machine or two machines. What it does is transfering .gitignore file to the other end. Here's its GUI:
To run this app, npm install first, then launch it following node-webkit's documentation. Assume you only have one computer, click the receive button, then click send button, you'll see a new file called received_gitignore appear in app's directory. Be sure to click receive before send, whether running on single machine or two machines.
Finally, let's get down to business to explain how this demo works.
First is package.json:
{
"main": "main.html",
}
So main.html is the first HTML page node-webkit should display.
<html>
<script>
var main = require('./main.js');
window.location.href = "http://127.0.0.1:12345/";
</script>
</html>
Here's the interesting part: our main.html doesn't contain anything to display, it's only purpose is calling require('./main') which will launch an express server listening on 127.0.0.0:12345, then connects to it.
Let's see how it's done in main.js:
// main.js part 1
var app = require('express')();
var server = require('http').Server(app);
var io = require('socket.io')(server);
server.listen(12345);
app.use(require('express').static(__dirname + '/static'));
app.get('/', function (req, res) {
res.sendfile(__dirname + '/index.html');
});
Nothing special, just a regular express http server with socket.io.
As we can see, visiting http://127.0.0.1:12345/ gets index.html displayed. Here's index.html:
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<meta name="author" content="laike9m">
<title>demo</title>
<script type="text/javascript" src="peer.js"></script>
<script type="text/javascript" src="/socket.io/socket.io.js"></script>
</head>
<body>
<script>
window.socket = io.connect('http://localhost/', { port: 12345 });
function clickSend() {
var peer = new Peer('sender', {key: '45rvl4l8vjn3766r'});
var conn = peer.connect('receiver');
conn.on('open', function () {
console.log("sender dataconn open");
window.socket.on('sendToPeer', function(data) {
console.log("sent data: ", Date());
conn.send(data);
peer.disconnect();
});
window.socket.emit('send');
});
}
function clickRecv(){
var peer = new Peer('receiver', {key: '45rvl4l8vjn3766r'});
peer.on('connection', function(conn) {
conn.on("open", function(){
console.log("receiver dataconn open");
conn.on('data', function(data){
console.log("received data: ", Date());
window.socket.emit('receive', data);
});
});
});
}
</script>
peerjs with nodewebkit demo
<button onclick="clickSend()">send</button>
<button onclick="clickRecv()">receive</button>
</body>
</html>
It contains two button: send and receive. When clicked, clickSend and clickRecv gets called. To understand what these functions do, let's see the other part of main.js.
// main.js part 2
io.on('connection', function(socket){
socket.on('send', function(data){
socket.emit('sendToPeer', fs.readFileSync('.gitignore'));
});
socket.on('receive', function(data){
fs.writeFileSync('received_gitignore', data);
});
});
So you clicked the receive button, PeerJs create a Peer with id receiver and a valid key I registered, then it waits for connection from sender. Then you clicked the send button, another Peer is created with id sender. sender tries to connect to receiver and when data connection successfully built, window.socketemits a send event, which is handled in main.js. The handler simply reads file content and sends it back to DOM environment. Note that socket.io supports binary data transfer from version 1.0, so you can't use a lower version socket.io.
Coming back to code in clickSend, we've already created an event handler on sendToPeer before emitting send event, now it gets fired. conn.send(data) sends data to Peer receiver. In function clickRecv, when conn receives data, it uses window.socket to emit a receive event and sends data from sender to Node runtime. Finally fs.writeFileSync('received_gitignore', data) write data to disk, all done.
You might wonder if it actually works for large file transfer. It does. My project is working great, it can transfer large files with decent speed, the prototype is this demo. Of course you should write many many more lines to make this prototype a usable app, for instance, data needs to be sliced when transfering large files, and you should handle all kinds of PeerJs errors.
That's all for this tutorial.
