想理解 HTTP/2,目前还没有什么比读 RFC 更好的方式。不过 RFC7540 有些地方写的不够清楚,我花了很长时间才搞明白,故在此记录一些想法,请随 RFC 一起阅读。几点说明:
- 本文及后续文章中的章节号、Page x 均指 RFC7540 中的章节号和页码;
- 从实用性角度考虑,h2c only 的内容不太会涉及;
- 因为是笔记,所以基本只会写个人认为值得讨论或注意的地方,也会有一些总结;
- 不涉及 RFC7541,即 HAPCK 头部压缩;
- 不想翻译或不好翻译的术语不翻译;
- 有时用 frame 类型名指代这种类型的 frame,比如“发送 HEADERS”指的是发送 HEADERS frame。
1. Introduction
2. HTTP/2 Protocol Overview
最基本的介绍性内容,也是网上大部分相关文章的深度。只想了解的话,读这两章也就够了。如果想继续阅读,2.2 节中的名词解释很重要,介绍了 "MUST", "SHOULD" 等词(参考 RFC2119),以及 client, connection, endpoint, peer 等术语的含义。
3. Starting HTTP/2
3.5 HTTP/2 Connection Preface
client preface = 0x505249202a20485454502f322e300d0a0d0a534d0d0a0d0a + SETTINGS frame
server preface = SETTINGS frame(默认是空的)
h2 client 的 preface 是 TLS connection 传输的 data 的第一段(server 也是),允许在接收到 server preface 之前发送其它数据,比如比如 HEADER,别的 setting,这样省去了等待 server preface 的时间。
两边的 preface 都需要对方发送 ACK frame 进行确认,ACK 是一种特殊的 SETTINGS frame,参见 6.5 节。
4. HTTP Frames
4.1 Frame Format
frame 基本结构是 9 字节的 header 加上不定长的 payload。header 的第一部分是 payload length,占 24 位,也就是说 payload 最多是 2^24 - 1 字节。这个 payload length 有初始值,是 2^14,如果想提升这个值得靠 SETTINGS_MAX_FRAME_SIZE,参考 Page 39。还有一点就是 header 的 9 个字节是不计入 payload length 的。
Flags 在不同的 frame type 下含义是不一样的,每一位并没有固定的含义。
Stream Identifier 即所谓 stream ID。在 RFC 及我后续的笔记当中都经常会用到“frame 在 stream A 上发送”这种说法,实际上指的就是某个 frame 的 stream ID 是 A。
从很久以前我就在思考一个问题:
到底什么时候去秋叶原?
因为对于像我这样的人来说,并不存在要不要去的问题,问题只在于什么时候去。然而还没等得出结论,我已经随着团队 off site 来到了东京。穿梭于繁忙的地下铁路,在新宿、涩谷走走逛逛吃吃喝喝。那是 2016 年 10 月 23 日的一个下午,我们在地铁站下车,出站。走在前面的 K 突然转过来,“我们到了,前面就是秋叶原。”天色已渐渐变暗,巨大的霓虹灯招牌堆叠在并不宽阔的道路两边,闪出五颜六色的光。我抬起头,突然有一种不真实感。
……
好吧,其实是鬼扯的,并没有想那么多——因为 K 说门口就是广播会馆,我便急着去照相了。K 是东京本地人,也是秋叶原老司机。刚踏出地铁站,他便宣称”欢迎来到我家“,令我们一行人钦佩不已。有老司机带路自然走得快,于是其它人都钻进 Yodobashi 开始买买买,毕竟那里号称没有买不到的东西;我则去 Animate,因为 K 说他觉得那里很不错。
这时就显出准备之仓促了……我不知道该买什么,更不知道在哪里买。Animate 是一个综合性的大店,我去的那家有七层之多,整个楼都是他们的。至于商品呢,简单来说就是什么热门上什么,最热门的摆在最显眼的地方。文豪野犬低音号,那必然给好位置,刚完结的大热作品 New Game! 也不能少。基本上近两年内的作品都很容易找到,长盛不衰经典作品比如柯南海贼NANA也有。印象比较深的是看到了《无限之住人》,因为刚完结,所以直接重新出了一版,共五本,每本都巨厚。我前不久才看完,于是差点想剁手,掂量一下厚度还是忍住了。另一个有意思的是顶层的卡牌区,有一些人坐在那对战,除了一桌游戏王剩下的都没见过。几个架子满满地全是卡,居然看到了 SHIROBAKO 的卡牌?!不是在逗我吧。仔细一看,似乎很多卡只是样品,要预定才会出?旁边还有 Love Live! 的卡,不过这个也算在预料之内,没有才奇怪。这就是商业化啊。
第一天两个小时只够把 Animate 逛一遍。但还是买了一些东西:

逆转和 New Game! 就不用介绍了吧。重点是下面的

我曾经写过一篇文章评论《屋顶上的百合灵同学》,至今仍是博客里唯一的游戏评论,而这两本是游戏的官方漫画。在书架上看到时,我一时不敢相信,感觉捡到宝了。A、B 两册分别由伊藤ハチ和文尾文执笔。伊藤ハチ在业内也是名人了,不知是被游戏吸引还是约稿,总之我觉得他的画风真的挺适合百合灵的。
回到宾馆,我不敢休息,插上充电线开始边 Google 边想到底该买什么。其实不是不知道买什么,而是得在太多可以买的东西里选出最值得带回去的。不知道其它人怎么想,但本命作品没买却买了一大堆只是看过的,我绝不能让这种事发生。书包容量也有限,没带箱子挺失误的。还有就是想着国内买的到的东西还是别在日本买了。就这样,最终选定了三类东西:
- OST
- 百合漫中没有台版的
- Cowboy Bebop, FLCL
这里有一件很有意思的事:已买的和想买的东西都是我以前就玩过/看过/听过的作品。是啊,我知道盗版是个老生常谈的问题,但当我真正去秋叶原买东西,把内容早已了然于胸的作品拿在手上时,确有一种未曾体会过的奇异感觉:漫画一页一页翻起来的手感很棒,图片看起来比扫描的更加舒服,日文我不能都看懂,却知道下一页要发生的故事;蓝光碟被精美的封皮包裹,能够感受到重量,不能拆开的碟片里,是我脑中连贯的映像。有些事情的因果被颠倒,现在修正的时刻到了。
出于种种原因,我们确实很难购买到正版作品,而且很多东西价格也不太 affordable。这时候,如果不看,那么就不知道某部作品;如果知道了,那肯定是通过盗版。所以我对盗版动画/漫画/CD的态度是这样:可以免费看,但一定要谨记我们是在免费享用别人的劳动成果,保持感激,心怀愧疚。好消息是现在新番基本都有正版了,所以今后成长起来的中国宅们在动画方面其实没有多少原罪。然而,漫画和 CD 这些更加小众的商品,依然是不太可能引进的(没有人愿意干亏本买卖)。这正是为什么我非常欣赏布卡,并愿意在这儿给它打广告的原因,后面详细讲。
第二天参观完贵司 office,我又来到了秋叶原。这一次目标十分明确,不仅想好了要买的东西,连要去的店都查好了,包括 Book-Off、K-BOOKS、Mandarake、Toranoana 和 TRADER。
第一站 Book-Off
Book-Off 是个二手连锁书店。一层主要买动画 BD,二层及以上是各种二手书,包括大量漫画。一层柜子上贴着商品清单,显示有卖星际牛仔的 BD,但我没找到,最后是让店员帮忙找的。还有一层专门卖 CD。之前我把想买 CD 在虾米上收藏了,有这些:

本以为 CD 很好买,毕竟电影里的 CD 店总是有夸张的存货数量和一个不论什么碟翻几下就能找出来的老板,而且这几个 OST 都不算冷吧(对 CD 店来说)。然而我很快见识到了现实的残酷。店员看一个找一个,过了十几分钟,一个也没找着……”すみません“,他已经尽力了。
第二站 K-BOOKS,所在位置是——广播会馆!不过 K 说前几年会馆重建了(╥﹏╥),现在看到的已经不是动画里的广播会馆了。这也是命运石之门的选择吧。上三层找到 K-BOOKS,和 Animate 类似,显眼位置都摆放着近年的作品。走到墙边,发现芳文社占据了一个大书架。难道这家店有百合区?但并没有看见一迅社和双叶社的影子。感觉奇怪便 Google 了一下,原来芳文社就在东京。走过芳文社的书架,整个墙的颜色开始变得奇怪了(*/ω\*),老司机们应该知道我的意思。鉴于对里番没什么兴趣,我没逛就直接走了。走到这一层的另一边,看见书架上密密麻麻插了一堆标签,走近了才发现是一些作者和社团的名字。然后我突然意识到,这一区域全都是本子!说来奇怪,去秋叶原之前我满心想着找本子,还问同学有没有想买的,结果晚上做规划居然忘记了!不过老司机推荐的店就是不一样(没错 K-BOOKS 也是 K 推荐的),这里我可以负责地说,K-BOOKS 对本子的分类是真好。不仅有按社团和作者分类,还有按作品和人物分类的,果然地方大就是好。虽然我看过不少,但是书名和作者真的记不住,翻了半天都不知道怎么选,以及本子挤在书架上连抽出来都很困难。选定的第一本是神枪少女,封面是 Triela,原因之一是 GSG 里我比较萌 Triela/合榭 这一对,其二是 GSG 区只有两本书,感觉一下就珍贵起来了。第二本是助手本,嘛,毕竟来到了广播会馆不是……然而事实证明看封面选本子还是风险太大(书都有塑料袋包着,不买不能拆),这本很坑,更坑的是我还帮朋友买了一本。助手的本子不少,在一排中占了很大一段。紧接着就看见了更大的一段:秋山澪……不太想买轻音的本子就没挑,现在回想起来真是犯了 big mistake,难得去一趟怎么可以错过黑轻音呢。不过倒是在梓喵的区域仔细翻了翻,没有发现梓喵打酱油于是就算了(其实是不知道封面长啥样)。热门作品/人物基本都有,还有一个书架上全是东方本。时间紧迫,我叫住店员,直接给它看了三个名字:花咲くいろは、DARKER THAN BLACK、SHIROBAKO,并且用英语告诉他我想找这些,因为在我印象里这三部作品有一些质量不错的。很快就指了三个位置,萨斯噶。然后我就开始挑……这时候,不知该怎么形容,我的头脑逐渐开始发热,感到某种限制似乎正在一点点解除,手也慢慢控制不住了。一本、两本、三本,我终于体会到了女生买买买的快感,那是一种看到好东西就绝不放过的执念,是如果看价钱就输了的决心,是如果犹豫要不要买最后一定会买的决断。我又想起了笹原第一次逛 CM 的情景,木尾士目老师您太厉害了,我们这帮人真的就是这样无可救药啊。

本子就只能这么拍了,你们懂的。
K-BOOKS 也有一层专卖 CD,同样无果……看起来很有经验的店员找到一张神枪少女游戏的 CD 以及另一张,不过都不是我想要的。
下一站是网上好评的二手店 Mandarake。店坐落在秋叶原主干道延伸出去的一条不起眼小路上一个不起眼的街角,层与层之间通过架在墙外的楼梯连接,商品多种多样,漫画、周边、男性向、女性向都有专门楼层。CD 自然要问,不过我已不报希望,最后果然一张都没找到。好在收获仍然有。

FLCL 的 BD!这可能是本次秋叶原之行买到的最稀有物品?大概全中国也不超过十个人有吧。这套 BD 被放在墙上一个玻璃柜里,仿佛不是商品而是展览品,是店主意识到了它的价值,又或许是专程来寻找它的人太多?如同店里的其它二手商品一样,碟片被密封在一个塑料壳内,卖的时候才打开并取出。付款时,店员会问你还会不会在店内继续购物,如果不会,那么该商品就可以免税(当然是对外国人)。然而当时并不能直接拿到货,你得去一层取,并且护照会被很羞耻地订上一张字条。简直罪恶的印记啊(手动再见
接下来去 Toranoana,事后我才意识到是虎穴,这便是不会日语的悲哀了。虎穴有三个店 A、B、C,卖的商品完全不同。我问了一串路人才找到 A 店,居然是在一个楼的二层?连个显眼的标志都没有。A 店以热门商品、里番和男性同人志为主。B 店招牌最为醒目,店也最显眼,似乎主打女性向。但是我要找的百合漫在哪里?网上有外国人说虎穴有百合区,还放了照片,结果 A、B 店的店员却完全不知情。难道没有了么?此前已有耳闻百合近年之式微,然而仍未料想已到如此地步——之前逛的店几乎就没看见此类作品,相反 BL 则到处都是。我心里边叹气边走进 C 店,这是最后的希望了。还好还好,秋叶原的沙漠中仍然有一片不起眼的绿洲,传说中的百合区终于让我给找到了。C 店的一二层最里面相同位置各有一片,二层略多。即使是百合区也要按照商业法则,最好的位置依然要让给连载中作品的单行本。此时此刻,我最想说的却是:感谢布卡!
在布卡引进《百合姬》时,我写过一个回答:
当时我的状态是这样:《Citrus》啊,呵呵呵呵摆这么好的位置,然而之前已经批评过了;啥?《捏造trap》出单行本了,这种烂作会有人买?《2DK、G笔、闹钟》是不错的作品,要是出完了真想买一本。等会儿,好像哪里不太对,我一个外国人怎么和日本读者没什么差别了…………
这便是我感谢布卡的原因,它让我,让中国的读者们也能看到最新的杂志,LEGALLY。非要说这和看盗版有什么不同,首先是更新速度基本和日本同步,其次便是心理感觉了——看正版肯定是更舒服的。直到今天,百合姬依然对用户免费,为表支持我还是充了 50 块信仰费。
虎穴虽然地方不大,东西还是相当丰富的。除了一迅社的作品,还有一些其它连载中漫画的单行本,比如双角关系、无名的星群、乙女帝国等等。已完结作里则囊括了不少知名漫画家,不那么大众的像コダマナオコ、伊藤ハチ、百乃モト、竹宮ジン的作品基本齐全,更广为人知的比如玄铁绚的《星川银座四丁目》、志村贵子的《青花》也都摆放在列。更有大把我听都没听过的作品,反正很多就对了。我不太想买已经出了台版的那些,所以一边淘宝一边选,如果有就 pass。但只有一部作品,即使有台版,我还是想收一套:《Girl Friends》。我实在是太太太喜欢这部作品了,在我心里这就是百合漫的顶峰和标杆。但是啊但是,偏偏就这部不全,只有第一二卷。我只能不甘地买下第一卷聊以慰藉。下面就是在虎穴的收获,毕竟还是要考虑一下预算,没有放开买:

既然本来博客里就有百合漫推荐系列,就顺便介绍+无脑推荐一波吧。按从上到下从左到右编号为 1-9。第 1 本是《残光噪音》、2 和 3 是《我所不知的我的未知》、4 是《双角关系》、5 是《合法百合夫妇本》、6 是 Girl Friends 第一卷、7 是《恋爱漫画》、8 是《小公主的秘密》,9 是个短篇集。写到这我又想了一下,《Dear My Teacher》和藤枝雅的书应该再仔细找找的,还有就是《百合の世界入門》翻了一下但忘了买,这是本很不错的名作介绍,而且是 16 年十月出的非常之新。
本来是想从视频里截一些店面的图放上来,但是某号称智能的摄像机在导入时遇到了各种问题,我也已经花了太长时间来写文章,所以,先这样吧,之后如果弄好了再加上去。本文的图有点大,为此特意注册了七牛,要是加载不出就多等会吧。
最后,几条建议给想去秋叶原购物的同学:
- 一定请事先查好要买什么,如果能确定哪里能买到就更好了
- 买 OST,还是网购吧
- 买东西不会日语完全 ok,实际上一句话不说都可以
- 封面或名字(日语),两者至少得记住一个
- 想买本子的话,记住社团名找起来会很快,不是所有店都有人物和作品的分类
- 据说在店里对着商品照相不太好
zhihu-card 又有几个新用户了!
Polo's Blog
xlzd杂谈
小狐濡尾
Tian Jun
其实有些并不是新用户,只不过我上次没发现。Redis 里还有几条别的用户记录,但并未找到个人网站。
这篇文章主要讲什么呢?国庆及最近几天大改了后端架构,并且开源出来,所以就来说一说。这篇文章在我看来价值并不大,因为并没有包含多少探索的过程,不过姑且做个记录。
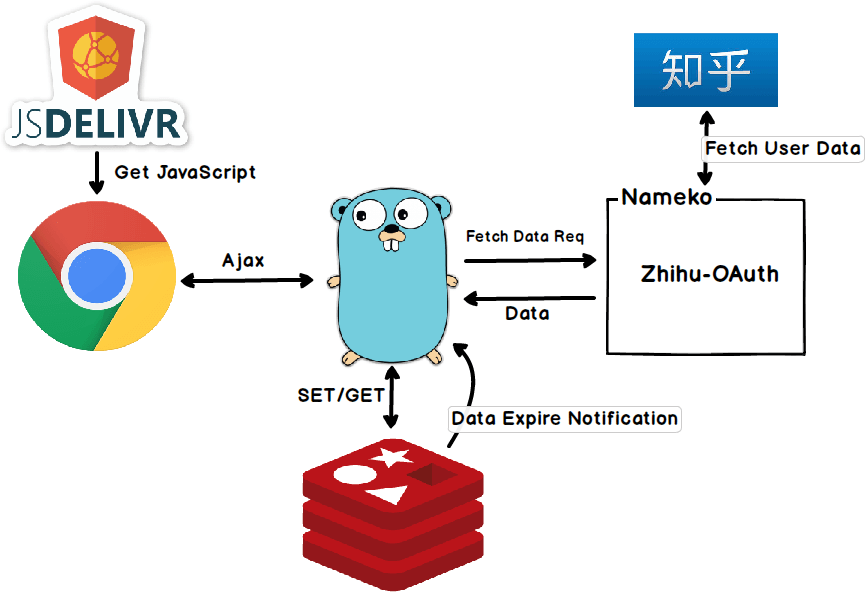
目前的架构长这个样。
jsDelivr 和 Chrome 的部分都在 zhihu-card 项目里,不是本文重点,总之后端会接收前端发的请求,并返回用户数据。
后端主要就三块,一个 Golang 的 HTTP Server,一个 Redis,一个 Nameko 的 local server。Go server 和 Redis 的交互就是很普通的 GET/SET,Redis 在 key 过期的时候会给 Go server 发通知让它去更新数据。不论是获取新用户数据还是更新已存在用户的数据,Go server 都是通过向跑在本地 Nameko server 发送一个请求,由 Nameko server 返回最新的用户数据。
OK,那么 Nameko 是什么?我最早是从大名鼎鼎的 Flask 作者 Armin Ronacher 的博文知道的,当然他并不是主要贡献者。Nameko 是一个用 Python 写的微服务框架,接口设计非常简洁,基本看一分钟文档就能上手。在做毕设的过程中我一度想尝试,不过后来发现需求不同转而使用了 huey(顺带一提 huey 也是个好东西,一个超轻量级的 task queue,该有的都有用起来也很稳定)。
所以为什么要用 Nameko?主要是因为我想用 zhihu-oauth,这样就可以省去因为知乎前端变动带来的代码修改工作。zhihu-oauth 是 Python 写的,那么 Nameko 就非常合适了。本来也不是说一定要用 zhihu-oauth,如果有 Go 的 zhihu oauth 客户端更好,这样连 Nameko 都不需要,但是没有啊。另外我对维护者 7sdream 同学的代码水平和修 bug 速度还是很有信心的,感谢他的出色工作。
在这次大改之前,后端会在请求到来时检查 Redis 中有无对应数据,如果没有,就把知乎的个人主页抓下来,提取数据存入 Redis 并返回给用户。这么做有两个问题,其一是知乎前端一变我就得改代码,其二是速度——每个 hit 到 cache miss 的访问者将不得不额外忍受一个访问知乎个人主页的 RTT。虽然不是大问题,但总觉得不爽。现在和知乎的交互全交给 zhihu-oauth 去做,速度比 GET 网页快很多。另一方面,由于 Redis 在 key 过期时会通知 Go server 并获取最新数据,因此对于已存在的用户,Redis 中总是有数据的,进一步减少了访问耗时。这个结论只在数据很少的时候成立,根据 Redis 文档,key expire 是每秒检查 10 次,每次 20 个:
Specifically this is what Redis does 10 times per second:
- Test 20 random keys from the set of keys with an associated expire.
- Delete all the keys found expired.
- If more than 25% of keys were expired, start again from step 1.
现在的数据量完全可以保证在 1s 内检查完所有 key。
zhihu-card-server 目前还不完善。上面我说 Nameko 很好,其实这个库用起来特别坑,有些很重要的事文档里是不写的。目前又遇到程序莫名其妙退出的 bug,还没有解决,只好先加上一个 fallback,在无法从 Nameko 获取数据的时候直接访问网页。还有 Go server 的异常处理,logging 这些也还没写……总之慢慢搞吧。
最后推荐一下我正在用的 markdown 编辑器 typora,前段时间正好在想类似功能,发现已经有人做出来了。简单来说,你不再需要左边 markdown 右边渲染了,渲染和文本现在放在一起,就好像在写 Word 一样。
