Update:
Use Logseq, period.
Update:
本来想换成国际版账号 + 本家客户端,因为最近国内版的同步速度实在太慢了,网页抓取经常同步不下来。况且本家客户端也有 dark mode 了,所以还好。至于 markdown,用了一段时间以后我发现很难用,所以基本上不会再在 Evernote 里用 markdown 记笔记了。
最后失败了。因为标签树没办法导出。傻逼 Evernote
印象笔记中国版毫无疑问是个更好的产品。
可能有不少人都知道,Evernote 的国内版“印象笔记”已经正式独立运营。作为 6 年老用户,现在我已经正式切换到国内版。这里需要澄清一点。Evernote 和印象笔记的账户和数据从一开始就是独立的,但在之前 App 是统一的。现在拆分之后,印象笔记有了自己的 App。
为什么要切换?很简单,因为中国版更好。目前发现有两点优势。
首先是 Markdown 支持。这个功能 Evernote 用户千呼万唤,但是官方一直冷淡应对。比如官方论坛上的这个帖子:Native Markdown Support
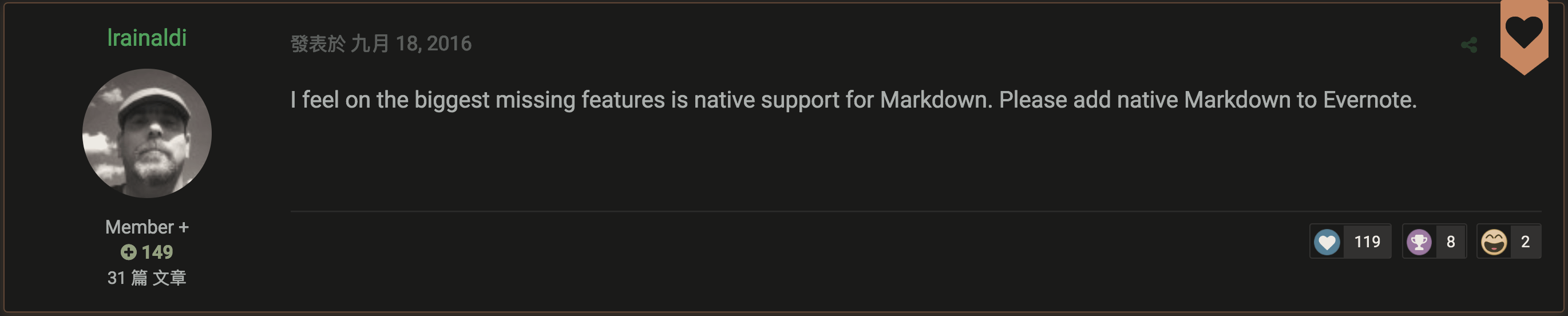
虽然回帖里众多用户强烈要求加入该功能,官方却一直没有回应。不少用户表示因为 Markdown support 的缺失,自己已转用其它笔记产品。
如果你用 Google 搜索 "Evernote markdown",会发现很多同类产品都瞄准了印象笔记的这个缺陷,把 markdown 作为自己的卖点,并且支持无缝 migrate。典型的例子如 Bear, Alternote。这两个产品我都没用过,所以也没法说个一二。然而我用过 Marxico/马克飞象 一段时间,这又是另一套解决方案了,即通过 Evernote API,使用独立于 App 外的编辑器实现 markdown 编辑,并在 App 内阅览。类似的还有 EverTool。这套方案虽然一定程度上解决了问题,用户体验却不怎么好,毕竟中间隔了一道。
好在终于有明白人意识到了这个问题。拆分之后的印象笔记添加的第一个功能就是 Markdown 支持。

虽然比不上 Typora,但也够用了。
另一个我很喜欢的新功能是对 OSX Mojave dark mode 的支持。Evernote 本家 app 在这点上非常令人失望,即使你开了 dark mode,整个程序界面还是像上图那样白得刺眼,简直没法用。为此我还尝试过第三方客户端 Tusk,效果也不尽人意。现在,有了新印象笔记,我的眼睛终于舒服了。

这才是我要的印象笔记,这才是一个产品该有的样子啊!我一直觉得,如果一个产品 or 功能在设计上给用户造成了困扰,或者不符合直觉,那么就是失败的。Evernote 本家的产品经理应该统统开除。
当然,作为私人笔记,安全性是重中之重。公认的说法是,印象笔记的信息存储在国内(在有独立 app 之前就是如此),所以理论上你的所有笔记对中国政府都是公开的。这就又回到那个老问题,即隐私和便利性之间的矛盾。这次我很不争气地选择了便利性。我有少量笔记涉及政治,姑且这些年还未被查水表。希望这不是一个 flag _(:3 」∠ )_
终于收齐了五卷尖端版 GF
。゚(゚´ω`゚)゚。

如果看过我以前文章,肯定知道我有多推崇这部漫画。自然,我想收一套实体书。日版随便一个电商网站上就有,但台版(尖端出版社)很难找。寻找的过程始于两年前。淘宝有店号称有,我下单,等了几个月都不见发货,只能退款。这个过程重复了三次,我放弃了。
巧的是,我们组在 2017 年末安排了一场台湾的 offsite。我当然不会放过这个搜索台北书店的好机会。我幻想着一个操着台腔的中年大叔老板从柜子里翻出尘封多年的漫画,笑着对我说:“小伙子,你可算找对地方了”。然而现实给了我当头一棒。找了四家书店,不知道是不是周日的原因,两家关门,另两家没货。至今还记得在台北搭乘公交,凭着 Google Map 跑过数个路口,最终却发现店门紧锁的那份失落。台湾之行,一无所获。
线下不行,再试试线上吧。搜索一番台湾的几个网站,几乎毫不费力地买到了 3、4、5。然而 1、2 卷虽然很多网站都列为商品,却无一家有货。毕竟第一卷是 08 年出的,第二卷是 09 年,距今快十年,肯定早就卖光了。于是只能暂缓。
一次偶然的机会发现TAAZE|讀冊生活这个网站,除了卖新书还卖二手书。它有个很棒的订阅机制,当你订阅了一本书的消息,书有货的时候就会给你发邮件。我看到 GF 一二卷过去有二手书成交记录,于是点了订阅。这是今年五月份的事。八月,邮件来了。
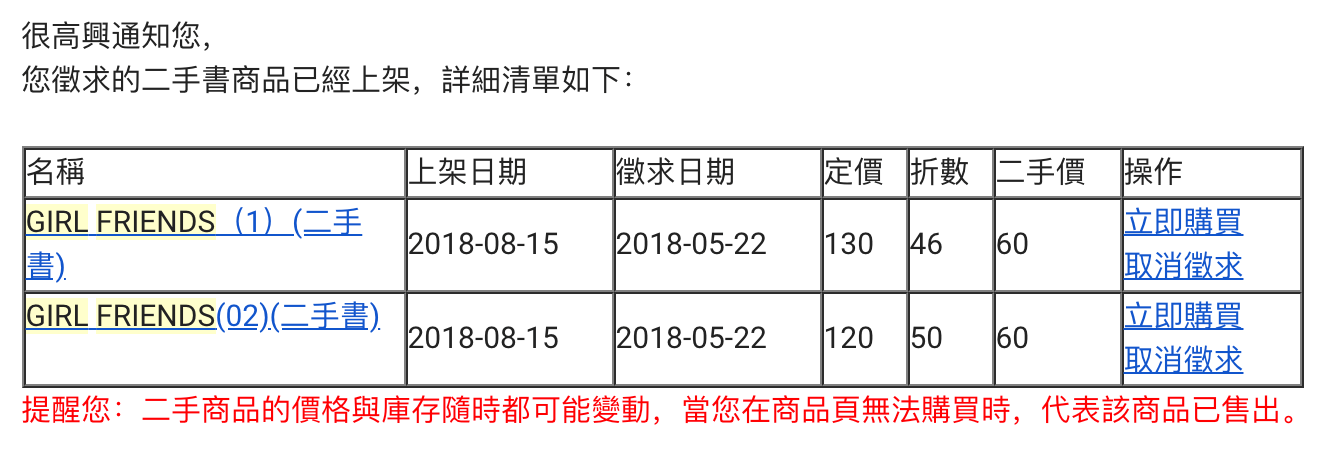
如果没记错,我当时没有第一时间看到邮件。点进商品页面,发现已经被别人抢了,并且同时还有几个人在求购。没想到二手书竟然抢得这么凶。我下决心下次一定要抢到,并调高了报价成为征求者里并列最高的。终于,就在前几天,邮件再次到来:
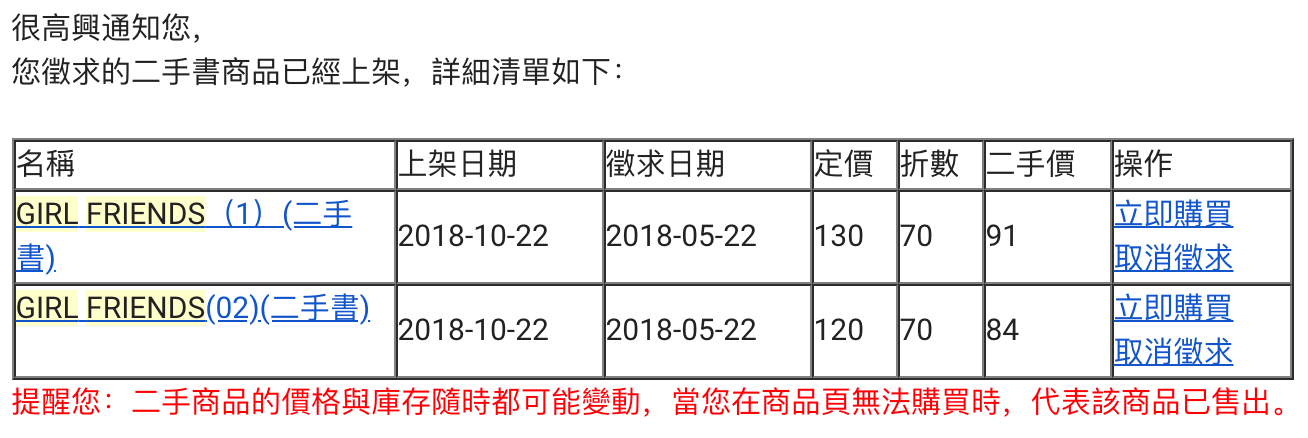
正好那天 work from home,啥都不说了,迅速下单,却被告知信用卡交易失败,再次尝试仍然失败。回到书籍页面,商品数又变回了让人绝望的 0。明明第一时间下手,明明都走到最后一步,却还是错过了吗?
不一会儿,收到一封新邮件:
您的訂單號碼:01810236387703
目前並未收到您的信用卡付款,系統已經取消您的訂單。
若您有任何問題,請與我們聯繫,謝謝您!
我马上意识到,如果他们的交易系统存在锁机制,即不允许有两个人同时进入交易,那么无货可能是因为我的交易在进行中,未必是真的没有。于是再次点进页面,果然有了。从家里翻出另一张信用卡,再次下单,终于成功。
买书的故事到这里就结束了,两年的追寻终于迎来圆满结局。如果不是因为那天恰好在家,说不定我就找不到可用的信用卡,也将再次错过难得的机会。做成事,有时候还真的需要一点运气。
简单发表一下通 SG0 的感想吧。(前方有剧透
个人感觉嘟嘟噜和真帆是最出彩的两条线。原来我对真有理不感冒,然而 SG0 让我喜欢上了这个角色。在真有理的路线中,她得知为了救自己,红莉栖被牺牲了,然后便毅然踏上了回到过去说服凶真的时间旅行。这封给凶真的信被缓缓念出的时候,我真的感觉有点想哭:

真有理并不是一个只会说嘟嘟噜的傻乎乎的女高中生,为了重要的人,她也会站出来。SG0 让人看到了她有勇气的一面,这是 SG 所没有展现的。

另一条线是真帆线。这条线和凶真关系不大,重点描绘了真帆和红莉栖作为研究所的前后辈之间的羁绊。同为天才少女,因为一首 K331 而真正熟识。红莉栖尊敬真帆,真帆却一度为自己比不上红莉栖而感到沮丧。萨列里和莫扎特,谣言并不真实,最后当误会被解开,真帆才意识到在红莉栖眼里自己也是重要的存在,可惜那时不论本人还是 Amadeus 都已经消失了。另外,莫扎特能让人集中注意力这点,我也算是很有共鸣了(写代码的时候听谁的歌比较好? - laike9m的回答 )。
教授和篝线中规中矩。
我不满意的是助手线。首先这条线太长了,打的时候一直在想怎么还没完。然后是回到 α 线那段简直莫名其妙,按理说这两条世界线的切换算是很大的事了,之后却几乎没有任何交待。这个插曲,给人感觉完全是为了让凶真再见一次红莉栖而设计的,非常突兀,仿佛在提醒玩家这是助手线。再就是,一个我认为可以展开好好描述的情节却又一笔带过了,说的是凶真从 2036 年经过 3000 次跳跃回到 2011 年那段。这段的感觉就是,胸针说我要跳了,3000 次!天哪好悲壮,中间到底会经历什么,是疲惫不堪精神崩溃,还是战火中游走在死亡边缘,感觉剧情高潮要来了。正期待着,突然就告诉你凶真跳回去了,中间发生了什么,你自己去想吧。卧槽,搞笑呢吧。日常剧情做一堆,关键剧情一笔带过,这算什么事!就是放几个静止画面概括一下也比现在要好。
还有个更大的问题,那就是篝这个角色。我不理解这个角色的设计。走散失忆洗脑啥的倒都还好,和真有理的母女羁绊描绘得也不错,问题是长相。输入红莉栖的记忆勉强还可以解释为为了套出时间机器的情报,但为什么篝要设计成长得和红莉栖一样啊?意义何在?如果玩家想回忆助手,看 Amadeus 就好了啊,反正随时随地都可以聊天,甚至真帆线里还有 Amadeus 也有 RS 的猜想,这点也可以展开啊。让篝长得像红莉栖,玩家就会把她视作替代品了吗?不会。基于此,这个角色我认为是失败的。而且,之前一直以为会爆出什么惊天秘密,比如篝是红莉栖的克隆什么的,也没有,长相完全一致这件事最后竟这么不了了之了,我都怀疑是不是忘写了。
对几条线的看法大概就这样。TE 没啥好说的中规中矩,感觉没做完(接真有理回到未来没讲),估计要么还有新作要么在动画里补完。就个人而言,我最 enjoy 的部分其实是由纪和铃羽,以及真有理和篝的互动,这种桥段真的是百看不厌(虽然好像和铃羽互动最多的那个由纪其实是篝假扮的)。对了,听真帆介绍 Frame problem 也是极有意思的。游戏的评价就先写到这,至于动画,似乎是把各条线糅合在一起讲,祈祷它能接近 SG 动画的高度吧。
