Revisiting Move Semantics(and all the related idioms)
- Value Semantics
- Move Semantics: V8 Engine on the Value Semantics Car
- Move Semantics and Performance Optimization
- Move Semantics and Resource Management
- But, resource is about identity…
- The Rebirth of Value Semantics
- Summary
While I was learning move semantics, I always had a feeling, that even though I knew the concept quite well, I cannot fit it into the big picture of C++. Move semantics is not like some syntactic sugar that solely exists for convenience, it deeply affected the way people think and write C++ and has become one of the most important C++ idioms. But let’s be honest, C++ was already crowded with lots of established idioms, and when move semantics showed up, things got a bit messy. Did move semantics break, enhance, or just replace some of those old idioms? I don't know, but I want to find out.
Value Semantics
Value semantics is what makes me start to think about this problem. Since there aren't many things in C++ with the name "semantics", I naturally thought, "maybe value and move semantics have some connections?". Turns out, it's not just connections, it's the origin:
Move semantics is not an attempt to supplant copy semantics, nor undermine it in any way. Rather this proposal seeks to augment copy semantics.
- Move Semantics Proposal, September 10, 2002
Perhaps you've noticed it uses the wording "copy semantics", in fact, "value semantics" and "copy semantics" are the same thing, and I'll use them interchangeably.
OK, so what is value semantics? isocpp has a whole page talking about it, but basically, value semantics means assignment copies the value, like T b = a;. That's the definition, but often times value semantics just means to create, use, store the object itself, pass, return by value, rather than pointers or references.
The opposite concept is reference semantics, where assignment copies the pointer. In reference semantics, what's important is identity, for example T& b = a; , we have to remember that b is an alias of a, not anything else. But in value semantics, we don't care about identity at all, we only care about the value an object1 holds. This is brought by the nature of copy, because a copy is ensured to give us two independent objects that hold the same value, you can't tell which one is the source, nor does it affect usage.
Unlike other languages(Java, C#, JavaScript), C++ is built on value semantics. By default, assignment does bit-wise-copy(if no user-defined copy ctor is involved), arguments and return values are copy-constructed(yes I know there's RVO). Keeping value semantics is considered a good thing in C++. On the one hand, it's safer, because you don't need to worry about dangling pointers and all the creepy stuff; on the other hand, it's faster, because you have less indirection, see here for the official explanation.
Move Semantics: V8 Engine on the Value Semantics Car
Move semantics is not an attempt to supplant copy semantics. They are totally compatible with each other. I came up with this metaphor which I feel describes their relation really well.
Imagine you have a car, it ran smoothly with the built-in engine. One day, you installed an extra V8 engine onto this car. Whenever you have enough fuel, the V8 engine is able to speed up your car, and that makes you happy.
So, the car is value semantics, and the V8 engine is move semantics. Installing an engine on your car does not require a new car, it's still the same car, just like using move semantics won't make you drop value semantics, because you're still operating on the object itself not its references or pointers. Further more, the move if you can, else copy strategy, implemented by the binding preferences, is exactly like way engine is chosen, that is to use V8 if you can(enough fuel), otherwise fall back to the original engine.
Now we have a pretty good understanding of Howard Hinnant(main author of the move proposal)'s answer on SO:
Move semantics allows us to keep value semantics, but at the same time gain the performance of reference semantics in those cases where the value of the original (copied-from) object is unimportant to program logic.
EDIT: Howard added some comment that really worth mentioning. By definition, move semantics acts more like reference semantics, because the moved-to and moved-from objects are not independent, when modifying(either by move-construction or move-assignment) the moved-to object, the moved-from object is also modified. However, it doesn't really matter——when move semantics takes place, you don't care about the moved-from object, it's either a pure rvalue (so nobody else has a reference to the original), or when the programmer specifically says "I don't care about the value of the original after the copy" (by using std::move instead of copy). Since modification to the original object has no impact on the program, you can use the moved-to object as if it's an independent copy, retaining the appearance of value semantics.
Move Semantics and Performance Optimization
Move semantics is mostly about performance optimization: the ability to move an expensive object from one address in memory to another, while pilfering resources of the source in order to construct the target with minimum expense.
As stated in the proposal, the main benefit people get from move semantics are performance boost. I'll give two examples here.
The optimization you can see
Suppose we have a handler(whatever that is) which is expensive to construct, and we want to store it into a map for future use.
std::unordered_map<string, Handler> handlers;
void RegisterHandler(const string& name, Handler handler) {
handlers[name] = std::move(handler);
}
RegisterHandler("handler-A", build_handler());
This is a typical use of move, and of course it assumes Handler has a move ctor. By moving(not copying)-constructing a map value, a lot of time may be saved.
The optimization you can't see
Howard Hinnant once mentioned in his talk that, the idea of move semantics came from optimizing std::vector. How?
A std::vector<T> object is basically a set of pointers to an internal data buffer on heap, like begin() and end(). Copying a vector is expensive due to allocating new memory for the data buffer. When move is used instead of copy, only the pointers get copied and point to the old buffer.
What's more, move also boosts vector insert operation. This is explained in the vector Example section in the proposal. Say we have a std::vector<string> with two elements "AAAAA" and "BBBBB", now we want to insert "CCCCC" at index 1. Assuming the vector has enough capacity, the following graph demonstrates the process of inserting with copy vs move.
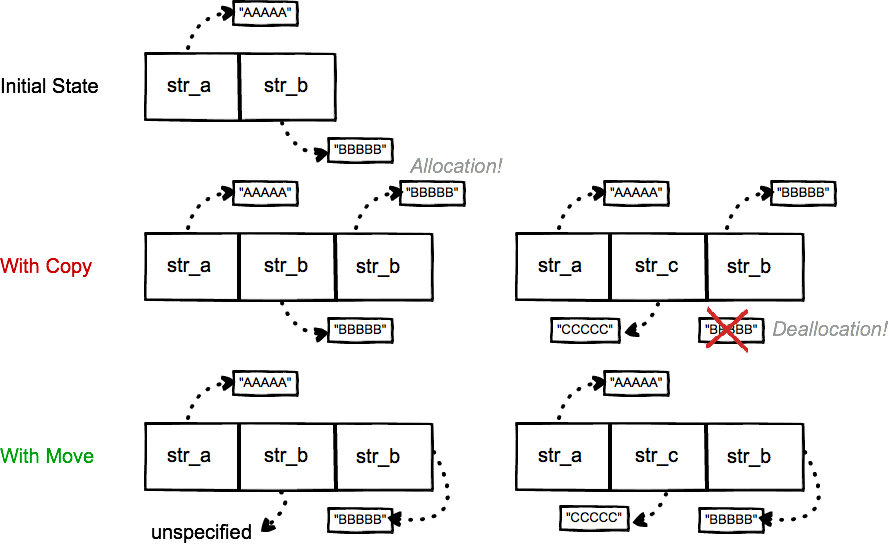
Everything shown on the graph is on heap, including the vector's data buffer and each element string's data buffer. With copy, str_b's data buffer has to be copied, which involves a buffer allocation then deallocation. With move, old str_b's data buffer is reused by the new str_b in the new address, no buffer allocation or deallocation is needed(As Howard pointed out, the "data" that old str_b now points to is unspecified). This brings a huge performance boost, yet it means more than that, because now you can store expensive objects into a vector without sacrificing performance, while previously having to store pointers. This also helps extend usage of value semantics.
Move Semantics and Resource Management
In the famous article Rule of Zero, the author wrote:
Using value semantics is essential for RAII, because references don’t affect the lifetime of their referrents.
I found it to be a good starting point to discuss the correlation between move semantics and resource management.
As you may or may not know, RAII has another name called Scope-Bound Resource Management (SBRM), after the basic use case where the lifetime of an RAII object ends due to scope exit. Remember one advantage of using value semantics? Safety. We know exactly when an object's lifetime starts and ends, just by looking at its storage duration, and 99% of the time we'll find it at block scope, which makes it very simple. Things get a lot more complicated for pointers and references, now we have to worry about whether the object that is referenced or pointed to has been released. This is hard, what makes it worse is that these objects usually exist in different scope from its pointers and references.
It's obvious why value semantics gets along well with RAII —— RAII binds the life cycle of a resource to the lifetime of an object, and with value semantics, you have a clear idea of an object's lifetime.
But, resource is about identity…
Though value semantics and RAII seems to be a perfect match, in reality it was not. Why? Fundamentally speaking, because resource is about identity, while value semantics only cares about value. You have an open socket, you use the very socket; you have an open file, you use the very file. In the context of resource management, there aren't things with the same value. A resource represents itself, with unique identity.
See the contradiction here? Prior to C++11, if we stick with value semantics, it was hard to work with resources cause they cannot be copied, therefore programmers came up with some workarounds:
- Use raw pointers;
- Write their own movable-but-not-copyable class(often Involves private copy ctor and operations like
swapandsplice); - Use
auto_ptr.
These solutions intended to solve the problem of unique ownership and ownership transferring, but they all have some drawbacks. I won't talk about it here cause it's everywhere on the Internet. What I would like to address is that, even without move semantics, resource ownership management can be done, it's just that it takes more code and is often error-prone.
What is lacking is uniform syntax and semantics to enable generic code to move arbitrary objects (just as generic code today can copy arbitrary objects).
Compared to the above statement from proposal, I like this answer more:
In addition to the obvious efficiency benefit, this also affords a programmer a standards-compliant way to have objects that are movable but not copyable. Objects that are movable and not copyable convey a very clear boundary of resource ownership via standard language semantics …my point is that move semantics is now a standard way to concisely express (among other things) movable-but-not-copyable objects.
The above quote has done a pretty good job explaining what move semantics means to resource ownership management in C++. Resource should naturally be movable(by "movable" I mean transferrable) but not copyable, now with the help of move semantics(well actually a whole lot of change at language level to support it), there's a standard way to do this right and efficiently.
The Rebirth of Value Semantics
Finally, we are able to talk about the other aspect(besides performance) of augmentation that move semantics brought to value semantics.
Stepping through the above discussion, we've seen why value semantics fits the RAII model, but at the same time not compatible with resource management. With the arise of move semantics, the necessary materials to fill this gap is finally prepared. So here we have, smart pointers!
Needless to say the importance of std::unique_ptr and std::shared_ptr, here I'd like to emphasize three things:
- They follow RAII;
- They take huge advantage of move semantics(especially for unique_ptr);
- They help keep value semantics.
For the third point, if you've read Rule of Zero, you know what I'm talking about. No need to use raw pointers to manage resources, EVER, just use unique_ptr directly or store as member variable, and you're done. When transferring resource ownership, the implicitly constructed move ctor is able to do the job well. Better yet, the current specification ensures that, a named value in the return statement in the worst case(i.e. without elisions) is treated as an rvalue. It means, returning by value should be the default choice for unique_ptr.
std::unique_ptr<ExpensiveResource> foo() {
auto data = std::make_unique<ExpensiveResource>();
return data;
}
std::unique_ptr<ExpensiveResource> p = foo(); // a move at worst
See here for a more detailed explanation. In fact, when using unique_ptr as function parameters, passing by value is still the best choice. I'll probably write an article about it, if time is available.
Besides smart pointers, std::string and std::vector are also RAII wrappers, and the resource they manage is heap memory. For these classes, return by value is still preferred. I'm not too sure about other things like std::thread or std::lock_guard cause I haven't got chance to use them.
To summarize, by utilizing smart pointers, value semantics now truly gains compatibility with RAII. At its core, this is powered by move semantics.
Summary
So far we've gone through a lot of concepts and you probably feel overwhelmed, but the points I want to convey are simple:
- Move semantics boosts performance while keeping value semantics;
- Move semantics helps bring every piece of resource management together to become what it is today. In particular, it is the key that makes value semantics and RAII truly work together, as it should have been long ago.
I'm a learner on this topic myself, so feel free to point out anything that you feel is wrong, I really appreciate it.
[1]: Here object means "a piece of memory that has an address, a type, and is capable of storing values", from Andrzej's C++ blog.
comments powered by Disqus