Python 的 block stack
网上关于 Python block stack 的文章少得可怜,中文文章更是基本搜不着。block stack 是 CPython 中的重要概念,但其实现又比较繁琐,因此我会先跳过细节,讲一讲为什么需要 block stack。之后会贴一些链接,里面有更细致的讲解。本文假定读者对 Python 的字节码有基本了解,且针对的是 Python 3.7 版本。
作为预备知识,我们知道 Python 的解释器是基于栈的。以 BINARY_ADD 举例,这个指令把栈顶元素和与栈顶相邻的元素出栈、相加,并把结果存到栈顶。这个栈的官方名称是 "value stack",但很多地方也将其称作 "evaluation stack" 或者 "data stack"。这里显示出 Python 在暴露实现细节时的混乱——文档中并正式定义这个术语,而它却又被在文档中广泛提及,并且是总是以 "stack" 这个含糊的名字出现(都想提个 bpo 去改进文档了 >_<)。
言归正传,为什么要强调 "value stack",是为了和解释器中的另外两个栈区分开:它们分别是 call stack 和 block stack。Call stack 大家比较熟悉这里就略过了。下面正式介绍 block stack,为了能更清晰地解释其来源,我们先看一个例子:
if a == 1:
foo()
else:
bar()
作为解释器,该如何实现 if 功能呢?很简单,只要知道分支所在的位置,根据 a == 1 的结果跳过去可以了,比如我们可以用行号表示位置:
if a == 1 is True, jump to line of "foo()"
if a == 1 is False, jump to line of "else:"
解释器有代码位置的信息,它知道 line of foo() 和 line of else: 的值,因此完全可以把这两条规则直接写死。不论整个程序其它部分的代码有多复杂,这个规则都不会变。
再看这个例子:
for i in range(4):
break
foo()
请问 break 应该如何实现?是否可以像 if 一样,直接跳到 line of foo() 呢?
答案是不行,因为 break 的跳转受到程序其它部分的影响。比如我们加一个 try...finally...:
for i in range(4):
try:
break
finally:
bar()
foo()
这时程序的执行流程就变为了 break ⟶ bar() ⟶ foo()。可以看到,break 跳转是上下文相关的。如果解释器仍然想用 hard-code 的规则实现跳转,就需要对上下文进行全面分析,才能判断出跳转的位置。这会让解释器的实现变得复杂,性能开销也会很大。
为了解决这个问题,CPython 引入了 block stack。用一句话概括就是,CPython 使用 block stack 应对控制流和异常处理带来的跳转不确定性,它让解释器利用运行时信息和少量的固定规则即可实现正确跳转。我将解释 block stack 在这个例子中是如何发挥作用的,为了方便读者理解会将一些地方简化。
首先,解释器在遇到循环 for i in range(4) 会 push 一个 Block(LOOP, line of foo(), b_level) 的结构到 block stack。我们称这个结构为 block,因为它对应了一个代码块。block 包含的第一个重要信息是它的类型,此处为 LOOP,表示它是一个循环结构。第二个重要信息是下一个指令的位置,即“当代码退出 block 的时候,接下来要执行的代码在哪”,显然,这里是 line of foo()。
对于 try...finally... 同理,Block(FINALLY, line of bar(), b_level) 会被 push 到 block stack。这时候的 block stack 如下图所示。
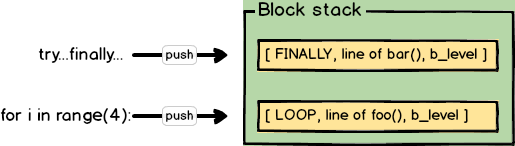
现在程序执行到了 break,解释器会根据当前执行的操作和栈顶 block 的类型判断它接下来要做什么。比如这里,当前执行的操作是 break,且 block 类型是 FINALLY,操作就是弹出栈顶元素 Block(FINALLY, line of bar(), b_level),并跳转到该 block 的下一个指令继续执行,也就是开始执行 bar。
当 bar() 执行完之后来到 finally 的结尾,解释器发现当前 block 的类型是 LOOP,且当前执行的操作是 break(这里比较 tricky,break 会被 push 到 value stack 上,所以现在还是可以读取的。我们只要知道解释器仍然知道当前的操作是 break 即可),则同样弹出栈顶元素 Block(LOOP, line of foo(), b_level),并跳转到该 block 的下一个指令 line of foo() 继续执行。此时 block stack 已被清空。
这里面有非常多的细节,我们可以先不去深究。关键是理解一点,即有了 block stack 之后,解释器只需要根据运行时的信息(当前执行的指令)以及先前 push 到 block stack 上的元素的信息(类型、下一个指令的位置),加上一些规则,就能够实现正确跳转。除了上面提到的几个 statements,try...except, continue, with 的实现都涉及 block stack,原因也是显而易见的。
本文仅为介绍 block stack 的概念,有意忽略了很多细节。因此下面列出一些材料,希望做深入了解的读者可以前往阅读。
dis moduel
Python 的 dis 模块。需要注意一下,Python 3.8 对 block 相关的 bytecode 做了较大改动,取消和新增了若干指令,但 block stack 的概念和作用没有变。《Inside The Python Virtual Machine》 Section 10. The Block Stack
我学习 block stack 的主要阅读材料。顺带一提本书可能是最被低估的 Python 书籍,没有之一。byterun 项目
用 < 1000 Python 行代码部分实现了一个 Python 解释器(主要是 evaluation loop 的部分)。建议首先阅读概述文章《A Python Interpreter Written in Python》,以便对字节码的工作方式和该项目有一个整体性的认识。之后可以阅读代码中和 block stack 相关的部分,基本上和 CPython 中对应的部分是等价的。ceval.c
CPython 的 evaluation loop 实现。请重点关注fast_block_end,它包含了 stack unwinding 的代码。限于篇幅我们没有过多介绍 stack unwinding。这个概念来源于 C++,在 Python 里指的是跳出一个 block 时需要做的清理工作(包括从 block stack 出栈、跳转到下一个指令)。清理工作其实还有另一部分,就留作思考题吧:请说明UNWIND_BLOCK这个宏的含义。我个人花了好长时间才看懂,要怪就怪b_level这个变量名起得实在是太烂了。
