其实我一直很喜欢Windows。作为一个OS,Windows可以说是成功得不能再成功了。普遍的观点是,Windows虽然适合使用,但是不适合做开发,所以程序员需要一个 *nix 操作系统的电脑。这么说自然是有道理的,在我看来,Windows不适合做开发,主要因为以下几点:
编码
搞Python开发的同学绝对被 Windows 蛋疼的 GBK 编码折磨过,更不要说 Python2 本身就存在诸多编码的坑,需要大量的经验或者指导才能够顺利跳过去。所以我后来有个强迫症,就是所有代码文件,不管里面有没有中文字符,统统弄成 utf-8,并且还写了个工具来把某个文件夹中所有内容转成utf-8。
CRLF
这一点其实还好,大多时候不会造成什么影响。就算是跨平台工作,问题也不大。顺便说一下我 msysgit 的设置一直是 line ending 强制转成 LF,checkout 的时候不修改。因为 Windows 下 \n 就可以正常完成换行工作。
shell 不够强大
这是致命的弱点。对于正常的程序员来讲,很多工作用命令行完成效率的确更高。好在有个工具能够弥补:GetGnuWin32。说实话,我认为有了 GetGnuWin32 之后,在 Windows 下做开发的障碍就扫清了不少(cmd.exe 太丑陋这点估计是无法改变)。但是还存在一个最大的障碍,就是第4点:
工具链缺乏
之前我没有意识到工具链对平台的影响,认为 Windows 之所以不适合做开发要归结于OS自身的问题。某天我偶然在 Youtube 上看到了 Jessica McKellar 的一个演讲 The Future of Python。她主要是在讲 Python 的话题,但是其中提到了重要的一点,就是 Python 用户在 Windows 上使用 Python 的时间不够多(毕竟大家主要还是在 *nix 上工作)导致 Python 代码的 Windows 版本(不论是 stdlib 还是 third party)都更新缓慢,并且存在大量未发现的 bug。实际上,导致我最终决定要买 Mac 的原因之一就是,之前某项任务需要的几个第三方库无论如何在 Windows 上都装不好。
工具链缺乏的问题,和平台本身的质量其实不应该混为一谈,在我看来,两者对于 Windows 作为开发平台的负面影响各占一半,而如果我们把 GetGnuWin32 以及 msysgit/clink/chocolatey/Vim... 这些东西都装到 Windows 上之后,其实前者的影响就已经很小了。如果要探究 Windows 工具链缺乏的原因,无非也就是两个,首先是历史原因,毕竟 Unix hacker 之所以叫 Unix hacker 是因为他们都在 Unix 下工作,再有就是恶性循环,工具链越缺乏,就越没有人在 Windows 下做开发,在 Windows 下做开发的人越少,工具链就越缺乏。为什么大家觉得在 Windows 上开发 C++ 还是不错的,甚至强于 *nix 平台,就是因为微软花大力气把 Windows C++ 开发的工具链给完成了,铺平了这条道路。
好吧,说了这么多,最后还是要抱怨一句:为什么Evernote不打算出Linux版??。我曾经花了很多时间研究怎么在 Linux 上顺畅使用 Evernote 或者类似产品,虽然取得了一些成效,但是结果仍然不满意(比如Wine下Evernote字体显示极为丑陋还有各种乱码,Wizbook 剪藏功能一坨屎,NixNote 客户端丑得没法看),最后只能勉强靠网页版度日。网页版用来浏览笔记是不错,编辑功能却烂的要命。可以这么说,如果印象笔记有官方Linux版,我绝对不会花钱去买 Mac。
PS: 有见过中学就开始编程且现在仍从事CS相关工作且编程水平一般的人吗?我感觉,从中学开始编程的人如果仍然在编程,不是大牛的可能性几乎是零。这让我感觉到,编程的学习其实是一个逐渐加速的过程(似乎很多人都这么觉得)。有时间看看能不能就这个问题写篇文章。
之前根据Django自带的缓存写了一个简单的缓存系统,针对views而不是页面,同时支持function based和class based views。因为并没有实际投入使用,所以只是个demo(但是测试过)。所有的代码都在一个文件里,参见 djangocachefor_views.py
Django缓存系统的介绍可见官方文档,这里用到的缓存方式是Local-memory caching,也就是说不依赖外部的数据库或者文件,直接把缓存放在内存中。使用方法如下:
在settings.py 中加入设置
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',
'KEY_PREFIX': 'kratos_server'
}
}
使用utils.py中定义的函数,需要在外部调用的有3个
generate_key, get_cachevalue, set_cachevalue
具体的参数请直接参考代码的注释
使用举例
@api_view(['GET'])
def cost_month_detail(request):
"""
获取某个成本某月的详细采购记录
"""
costs = Cost .objects.all()
item = request.QUERY_PARAMS.get('item', 'undefined')
cost_type = COST_TYPE_KEY_MAP.get(item, COST_TYPE_UNDEFINED)
month = request.QUERY_PARAMS.get('month', None)
key = generate_key('.' , *[item, month])
data = get_cachevalue(key)
if not data:
req_ym_str = month.split('.')
req_ym_int = [int(req_ym_str[0]), int(req_ym_str[1])]
if cost_type and req_ym_int:
costs = costs.filter( cost_type=cost_type,\
purchase_date__year=req_ym_int[0],\
purchase_date__month=req_ym_int[1])
serializer = CostSerializer(costs)
data = serializer.data
set_cachevalue(key, data, [models[item]])
return Response(data)
说明
Django的缓存在手动操作的情况下就是key-value的结构,添加、读取、删除,这几个操作Django已经封装得很好,无非就是 cache.add(key,value),cache.get(key),cache.delete(key)。关键之处在于,缓存的key要如何设计。我们当然可以对每一项需要缓存的东西事先定好key,比如有个Model叫做 Car,那么缓存数据库中全部车辆信息的key就叫做 car_info。这么做的问题在于,缓存项多了之后,容易搞混,比如我们希望缓存车辆价格信息,是不是又要弄一个 car_price_info 呢。而且在添加/获取缓存项的时候,如果每一个地方都要手动填写key,实在是非常麻烦又易出错。
要避免这种麻烦,只剩下一个选择,那就是自动生成所需要的 key,并且在读取缓存时,程序也能自己知道该用什么key去找缓存。自动生成key的代码,在 generate_key 这个函数里
import inspect
def generate_key(seperator, *args):
"""
:param seperator: key中的分隔符, 比如'-', '.'
:param args: 需要添加到key中的参数
:return: 生成的key
这个函数用来生成缓存的key, 有两种模式
1. class based view
会读取class name和method name
2. function view
会读取function name
最后用传入的seperator把所有东西, 包括args连接起来, 作为key返回
"""
key = []
frame_back = inspect.currentframe().f_back
func_name = frame_back.f_code.co_name
key.append(func_name)
if 'self' in frame_back.f_locals:
class_name = frame_back.f_locals['self'].__class__.__name__
key.append(class_name)
key = seperator.join(key + [str(arg) for arg in args])
return key
这段代码起作用的部分一共就9行,不过我自己都觉得看懂好难啊(:3」∠)。其实现在记下来的一个目的就是怕之后看不懂(雾。不如我们先看看效果吧:
假设有一个 function based view 函数 fbv:
def fbv(request):
...
key = generate_key('-', 'args1', 'args2')
...
先不考虑上下文,只关注生成key这件事。这里,生成的key是 fbv-args1-args2
再看一个 class based view:
class cbv(View):
def get(self, request):
...
key = generate_key('-', 'args1', 'args2')
...
这里生成的 key 是 cbv-get-args1-args2
现在,generate_key这个函数的效果就很清楚了,说白了就是把所有对生成一个有意义且唯一的 key 有帮助的信息用用户自定的分隔符连接起来,就得到了这个 key。这些信息包括:
- view 函数名
- class based view 类名(如果有的话)
- 用户自己添加的信息
如果用户懒得添加额外信息,那就直接 generate_key('-') 就行了,这样一来,每一个view函数都能够生成一个key,并且这个key具有唯一性,之后进行 add/get/delete 操作时,直接使用这个key就好,达成了我们希望的自动化。
那么生成key这件事到底是如何做到?我使用了 inspect 这个模块。之前没有用过它,为了这个任务不得已去看了看,结果发现 inspect 真的是非常强大,能完成好多看似不可能的任务。
由于这不是一篇讲 inspect 的文章,所以这块就不详细展开,看官方文档即可。要说的是三条语句所完成的事情:
frame_back = inspect.currentframe().f_back
获取当前堆栈帧的上一个堆栈帧,换句话说实际上就是调用generate_key函数的堆栈帧,也即view函数的堆栈帧func_name = frame_back.f_code.co_name
从堆栈帧里面读取代码信息,找到这段代码的名字,其实就是获取view函数名if 'self' in frame_back.f_locals:
从frame_back也就是view函数所在的堆栈帧读取local namespace,看看 self 是否在里面,用来判断这个view function是不是某个类的方法,即判断是否是class based viewclass_name = frame_back.f_locals['self'].__class__.__name__
如果是class based view,那我们就通过 self.__class__.__name__ 获取类的名字
以上就是缓存系统介绍的第一部分,之后应该还会写一篇,讲一下缓存如何和某个 Model 绑定以及缓存的更新。
今天是馆长死亡一周年的日子,虽然我很想写上“谨以此文,纪念天堂的馆长”这句话,但是很遗憾,不是一篇这样的文章。
本文由以下几部分构成:
1. 一年前的调查报告
2. 关于THU树洞上的虐杀宣言
3. 曾经的一篇报道
第一部分
这是我当时交给清华园派出所的文字,报案之后,因为他们想了解情况,所以就写了一份。
总的调查大概经历了三天,访问了不少人,包括图书馆的一些工作人员。比较遗憾的是没有能访问到李世雄,也就是负责喂养馆长的人,同时也是最后埋掉馆长的人。
以下是正文
关于清华图书馆“馆长猫”死亡事件的说明
关于事件的情况,在附上的新闻报道中已经有比较详细的描述。这则新闻报道基本可以认为是完全可信的。我主要对事件过程做一个概括,并加入目前调查的一些结果。此文中“图书馆”都指的是清华老图书馆。
一.事件经过
7月4日晚11点,图书馆保安周飞亚下班。他锁上图书馆的正门,从台阶侧面运送书籍的小门走出。此时猫被看见在右侧台阶上趴着。这是活的猫最后一次被人看见。
7月5日早6点,图书馆保洁员夏瑞琼发现猫死在老馆台阶左侧的草坪。这是死猫首次被人发现。
早8点多,猫饲养员李世雄将猫埋在了老馆大门西南方第一棵银杏树下。
二.猫的死状
可以确认的事实来自于夏瑞琼的回忆:
猫身上是干的,脖子和脑袋却是湿漉漉的。像是被水烫过,也像是被雨淋过。尾巴都翻上去了,看样子死了很久了。它的嘴张着,两只牙齿露在外面。猫身上有浮土和泥点,可能是昨晚下雨溅的。
同时可以确定,猫无外伤和掉皮现象。
另据在场同学称猫的头有变形。此说法未证实。
一.关于猫和图书馆
清华老图书馆可供猫出入的通道有三个:正门,运书的门,女厕所的窗户。关于女厕所窗户的情况来自于任婷唯同学,她曾多次看见猫从女厕所的窗户出入。窗户面向一块人无法从外面进入的区域,参见图1。图书馆的窗户基本都有纱窗并且无法打开,女厕所的窗户是目前所知唯一没有安装纱窗的窗户。
图书馆白天的工作人员较多,包括保洁员,老师,保安和饲养猫的大爷。在关门闭馆之后,仍有少量工作人员在馆内。这部分人的资料暂时空缺。
猫由李世雄喂养。猫和同学的接触极多,因为猫经常在自习室内走动或者睡觉。关于猫的情况可以概括为:懒,不怕人,吃东西很挑剔基本只吃饲养员给的,白天基本在馆内活动。另外,根据图书馆保安的说法,猫有时在馆内过夜,有时在馆外过夜。在馆内外过夜均无固定地点,即无法保证知道猫在晚11点到早晨这段时间内处于何地。据说猫不会走离老馆太远,此说法未证实。
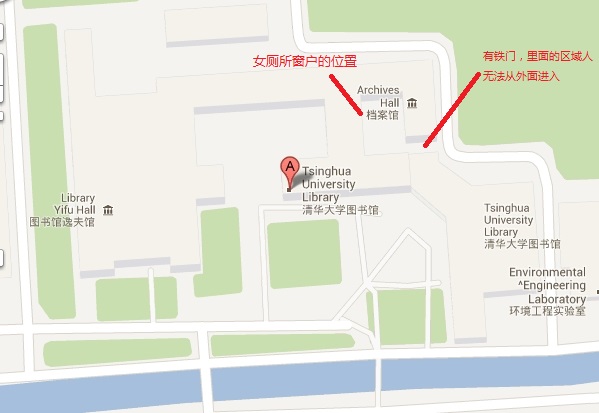
图1 图书馆俯视图
第二部分,关于THU树洞上的虐杀宣言
当我开始调查之后,某天晚上,有同学提到THU树洞上曾经有人说到要杀死馆长。以下是我们的聊天记录。未经允许把聊天记录贴出来,希望她能原谅。我一直很感谢她的这条线索,因为这可能是唯一能称得上实际“线索”的东西了:
00:54
唔?(°°)
同时也看到你留言说,看到过这个宣扬要弄死馆长的发言。但是我找了之前的树洞并没有看到,所以大概能请你回忆一下那条发言说了什么?以及是什么时间发的吗?非常感谢
=v =嗯~好的我想想
我印象中应该是考试周开始前或者刚开始的一两天
。。。。
然后。。
内容应该就是“我要猎杀馆长,你们等着吧”之类?
底下的回复就是lzsb之类
考试周是哪天开始的。。。大四狗表示不太清楚
。。。我的建议是你们找一个稍懂网络编程的人,从主页提取信息,搜索关键词"猎杀"或者什么之类
00:58
我虽然是计算机系的但是是个渣渣所以帮不上忙
像您现在这样肯定效率会很低
但是老实说就算找到当时的状态也几乎没办法找到真凶
亦或者说就算找到当时发树洞的人也没有办法断定他真的做了这件事
调人人的API说实话并不困难。。给我两天时间也可以做。现在还只是搜集更多的信息。
对。只是说从当时看到树洞状态的同学那里几乎是弄不到什么有用线索的。。。。只能 说。。。。找树洞作者才是最重要的。嗯,大概行不通。
对,这是肯定的,树洞要保护隐私。总之我会先找到这状态再说
嗯~O(∩∩)O
多谢提供帮助
01:04
^_^
第二天我花了很长时间去往前翻树洞的留言,毕竟已经过了一周。真的翻了很久,还好,并不是没有收获。我把文字复制下来了,但是鬼使神差地忘了截图。这是编号为16466的树洞留言:
#16466 猎杀馆长,我一会就把馆长首级挂在老馆门口
第三部分,一篇当时的报道
清华“猫馆长”今晨非正常死亡 去年就曾被烫伤
写在最后
事情已经过去一年了,到今天我才把一年前的资料发出来。本来,我是打算永远就这么留着这些资料的。今天看了看人人,除了一个状态之外没有什么关于馆长的内容。既然如此,就可以发了。
虽然有上面这些“调查”,但是至今,没有人知道馆长是怎么死的,甚至连是否自然死亡都不知道。后来,听北大猫协前会长雷九思说,他们那死掉的猫都是要拿去尸检确定死因的,而关于馆长,实际上自从饲养员李世雄在早上八点把它埋在树下那一刻起,真相也永远地被带进土里了。
我们不能怪李世雄。他自然是不会想到去尸检,就算他没有埋馆长,THU真的又有人想的到?又有人做得到?
然而清华园派出所,是我真正从情感上想责怪的,虽然没有人规定他们要对一只猫负责。前前后后跑了好几趟,以“伤害猫的学生也可能伤害人”及那篇报道说服了所长,拿到了口头上“会去看监控录像”的承诺。最后自然是石沉大海,了无音讯。我问他们监控的分布,被回绝了,试图拿到允许去调录像出来,也被回绝了,因为丢了自行车是可以去看录像的,但是猫死了,没有理由让你去。
人类总是健忘的,因为不健忘就会因为痛苦太多活不下去。馆长之死,乃至全国的各种曾经轰动一时的事件,都是一样。但是,我们又真的会因为别人而痛苦吗?
就这样吧。

