谋划已久的一篇文章,忙里偷闲终于能写出来。其实还有好多想写的东西,但是时间不允许。总之先把这篇写了。
要说的是三部漫画里面的几个我认为十分经典的镜头。
首先是《Girl Friends》21话。这一话讲述真理和男朋友分手然后和亚希表白。

我太喜欢最后亚希心理活动的那个描写了,如果要在看过的漫画里选出最佳心理描写,那就是这个了。
心脏砰砰跳的声音,比包厢里的音乐还要大声。
我那时心想,一定是因为我的麦克风开着。
某一次和别人聊天,我把这句话贴过去,说特别好,然后被鄙视说看得太少。聊天的这个人没看过《Girl Friends》,不过这句话仅看文字,也确实非常平淡。那么下面就分析一下到底好在哪。首先是描写有现场感,在画面的基础上,添加了声音的信息,从而让人很容易想象出KTV包间中听到真理表白从而心脏砰砰跳的亚希。最妙的地方在于,这里的心理活动虽然是第一人称的形式,但内容又是以第三人称的方式来叙述的,表达的意思是:你看,虽然我的心脏在砰砰跳,但是我还是很冷静的哦,而且,并不是因为我的心脏跳得太厉害所以声音大,而是因为麦克风开着,对,就是因为麦克风开着导致的。无法压抑激动的亚希,必须以这种方式来强行让自己不要被突如其来的惊喜冲昏头脑,如果只说第一句“心脏砰砰跳的声音,比包厢里的音乐还要大声”,也表达出了亚希很激动这层意思,但是如果没有后面那句,表达效果和深度都差了一大截。森永老师也确实是个天才,什么叫细腻,这就叫细腻。
第二个要说的是水上悟志的小众名作《惑星公主蜥蜴骑士》,不过其实直译的话应该翻作《行星的五月雨》。这部漫画是我看过的所有漫画中,我认为最燃的,没有之一。
本来想分析图的,但是算了,放个属于燃点之一的图吧。

以及之前写的一个短评:
最终战vs亚尼姆斯为何篇幅不够?
看完最终战我还以为漫画是被编辑要求在几话内结束导致剧情被腰斩,但仔细想想不是。为什么打亚尼姆斯草草收场,因为作者心中的最终战是骑士 vs 公主,打亚尼姆斯只不过是个前奏。前奏不能比正片更出彩,否则就不对了。为了放大最后五月雨把手放到夕日手上那一下的燃度/催泪度,必须让对战亚尼姆斯不要太显眼,这就导致了和最强 BOSS 的战斗看起来不太够劲。这是我觉得本作唯一遗憾的地方。
本作一开始感觉比较无聊,但是看了几卷之后就开始停不下来了。水上悟志是个对漫画节奏感有相当好把握的作者。比如他正在连载的的《战国妖狐》,就完美解决了大战之后要怎么从高潮收场的问题:他直接把主角换了。前一半故事里还是反派的人物,在大战之后变成主角,而之前的主角变成反派,而且这个转变还非常自然,并且也没有让故事的节奏突然变慢进入一个索然无味的状态。大战之后故事节奏处理不好的例子实在太多了,比如《东京食尸鬼》就是个失败的典型。当然也有像巨人那种每集都是爆点的漫画,不过大部分漫画节奏都还是有张有弛的,而水上悟志就是节奏掌控的专家。还有一点,水上悟志发便当从不会拖泥带水,不过他发便当的人,也不是随随便便就死的,一般是为了让另外一个人物成长。
说回本作,我觉得百度百科的评价很好“有燃有泪”,看进去的话,本作有不少地方是相当催泪的。我建议在找漫画补的人去看《惑星公主蜥蜴骑士》,这是一部可以让人燃到哭,感动到哭的作品。
最后说最近看完的《Touch》,我想对这部漫画不需要任何介绍。
这张图来自《Touch》第二卷:

这个图说的是浅仓南和上杉和也在餐馆吃(约)饭(会),达也和一个喜欢和也的女生从餐馆旁边走过去。和也和达也互相注意到了,但是两个女生都没发现,然后兄弟二人分别把两个女生的注意力转移开让她们没有发现另一边。看到这里,我就认定《Touch》一定是名作了,虽然之前我也知道。这张图什么意思?达也那边很好解释,因为此时他认为浅仓南是喜欢和也的,所以不想让那个女生去打扰他们。比较复杂的是和也这边,有两种解释:1. 他知道浅仓南喜欢达也,所以不想让她发现达也和另外一个女生走在一起; 2. 在 1 的基础上,和也认为,如果浅仓南发现了,就会很明显地表露出不满,这样会打破自己的希望因为虽然他知道南更喜欢哥哥一些,但是一直没有放弃追求南。另外如果南表露出态度,也会让南比较尴尬,因为她本身是想维持现状的。不管和也的举动要如何解释,这一幕都是相当神的,兄弟两个替对方着想的心情,通过这一幕完美体现了出来。
最后就是漫画史上最经典的表白场景之一:

这个没什么好说的,就是搁在这。
之前我一直不理解为什么浅仓南是国民女神。下面这段话摘自帖子浅仓南在日漫女主角中处于一个什么样的地位?
浅仓南是日本国民偶像。
TOUCH的漫画销量破亿,日本的销量破亿作品总共12部;TOUCH的平均每卷销量380万,仅次于海贼王,略高于灌篮和龙珠,日本的平均每卷销量400万级作品只此4部。
上次动画和特摄男女主角BEST50,浅仓南女性角色票数第一,十岁到六十岁年龄段都是票数前十;十年前朝日电视台全国调查人气动漫角色TOP100,浅仓南总票数第七,女性角色票数还是第一。只要投票面向大众,不局限于低年龄段的死宅,浅仓南轻松秒杀时下那些当红女性角色。
还有些高亮回复:
最喜欢的女主不容玷污
浅仓南给安达充刻画的完美,完美到让人对和也这种输家感到残忍。
很多上虎扑的都把赤木晴子当做心中的女神,但是说实话,仅仅对比人物的话,浅仓南估计能把晴子爆成龙珠中的那巴。
又比如
我会意淫千千万万个女角色,但是其中永远不会有她。
为什么漫画千千万万女性角色中会有这样一个特殊存在呢,只有看了《Touch》才能体会。
P.S. 宾治简直犯规!和也你死得好惨!
4.18 更新
目前 star 数已经达到 55 了,可喜可贺。
主要是因为去 reddit 发了一个帖子。发之前是25个star。之前没有去 reddit 宣传主要是感觉 reddit 门槛太高,geek 比较多,怕被喷。发觉 newsletter 这条路行不通之后,也没别的办法了,reddit 算是不得已的选择。从回复来看,reddit 比我想象的还是要友善不少,是个不错的地方。
这几个月断断续续地完成了一个名叫 ezcf 的库。可以直接 import .py 之外的文件格式,在我看来,还算有趣。所以原本的期望,是在 GitHub 超过 30 个 star,但现在看来,还是预期过高了。国内能宣传的地方差不多宣传了一遍,在 V2EX 发了帖之后,多少吸引了一些人,但是其他社区基本无效。然而真正让我没想到的是去 HackerNews 发帖居然连一个 star 都没增加。说实话,一个开源项目的好坏不取决于代码怎么样,知道的人多,用得人多就是好,这代表有人认同这个东西是有用的,而代码质量啊功能完善度啊都是可以逐渐改善的。没有人用的开源项目没有存在的价值。好在真正去看了项目的人,有几个对我说,“项目非常有趣”,这多少令人欣慰。
上周在推上@了 importpython,他说“pretty cool,下次放进 newsletter”。然而紧接着的 newsletter 里并没有。如果下次还没有,大概就真的没有了。
我感觉 ezcf 没有达到预期认可度的最大问题是,大多人第一眼都不知道它到底在干嘛。如果是列出几个函数的用法,写上输入输出,大家都很明白,问题是 ezcf 并不是这样起作用的,或者说,没法让人第一眼就知道 import ezcf 这句话起了什么作用,以及和之后的 import 语句有什么关系。说实话,一两句话根本说不清楚这个问题。其次是有直接 import 配置文件需求的人并不多。总而言之,没有办法快速展现出项目的有趣之处,这就是问题。
总之先放上地址
https://github.com/laike9m/ezcf
如果不写这篇博客,感觉无法释怀啊。顺便把 README 也放上来好了。
ezcf



ezcf stands for easy configuration, it allows you to import JSON/YAML/INI/XML
like .py files. It is useful whenever you need to read from these formats,
especially for reading configuration files.
OK, stop talking, show us some code!
On the left is what you'll normally do, on the right is the ezcf way. Much more elegant isn't it?

Install
pip install ezcf
If you run into error: yaml.h: No such file or directory, don't worry,
you can still use ezcf without any problem.
Supported File Types
ezcf supports JSON, YAML, INI and XML with extension json, yaml, yml, ini, xml.
Sample Usage
ezcf supports all kinds of valid import statements, here's an example:
├── subdir
│ ├── __init__.py
│ └── sample_yaml.yaml
├── test_normal.py
└── sample_json.json
Various ways to use configurations in sample_yaml.yaml and sample_json.json:
import ezcf
from subdir.sample_yaml import *
# or
from subdir.sample_yaml import something
# or
import subdir.sample_yaml as sy
print(sy.something)
from sample_json import *
# or
from sample_json import something
# or
import sample_json as sj
print(sj.something)
You can assume they're just regular python files.(Currently ezcf only supports files with utf-8 encoding)
What about relative import? Yes, ezcf supports relative import, as long as you use it correctly.
Something to note before using ezcf:
- ezcf is still in developement. If you find any bug, please report
it in issues;
- Be careful importing YAML which contains multiple documents: if there exists keys with the same name,
only one of them will be loaded. So it's better not to use multiple documents;
- All values in
.ini files are kept as it is and loaded as a string;
- Since XML only allows single root, the whole xml will be loaded as one dict with root's name as variable name;
- Namespace package is not supported yet, pull requests are welcome.
OK,如果你还在为并发(concurrency)和并行(parallelism)这两个词的区别而感到困扰,那么这篇文章就是写给你看的。搞这种词语辨析到底有什么意义?其实没什么意义,但是有太多人在混用错用这两个词(比如遇到的某门课的老师)。不论中文圈还是英文圈,即使已经有数不清的文章在讨论并行vs并发,却极少有能讲清楚的。让一个讲不清楚的人来解释,比不解释更可怕。比如我随便找了个网上的解释:
前者是逻辑上的同时发生(simultaneous),而后者是物理上的同时发生.
并发性(concurrency),又称共行性,是指能处理多个同时性活动的能力,并发事件之间不一定要同一时刻发生。
并行(parallelism)是指同时发生的两个并发事件,具有并发的含义,而并发则不一定并行。
来个比喻:并发和并行的区别就是一个人同时吃三个馒头和三个人同时吃三个馒头。
看了之后,你懂了么?不懂,更晕了。写出这类解释的人,自己也是一知半解,却又把自己脑子里模糊的影像拿出来写成文章,让读者阅毕反而更加疑惑。当然也有可能他确实懂了,但是写出这种文字也不能算负责。至于本文,请相信,一定是准确的,我也尽量做到讲解清晰。
OK,下面进入正题,concurrency vs parallelism
让我们大声朗读下面这句话:
“并发”指的是程序的结构,“并行”指的是程序运行时的状态
即使不看详细解释,也请记住这句话。下面来具体说说:
并行(parallelism)
这个概念很好理解。所谓并行,就是同时执行的意思,无需过度解读。判断程序是否处于并行的状态,就看同一时刻是否有超过一个“工作单位”在运行就好了。所以,单线程永远无法达到并行状态。
要达到并行状态,最简单的就是利用多线程和多进程。但是 Python 的多线程由于存在著名的 GIL,无法让两个线程真正“同时运行”,所以实际上是无法到达并行状态的。
并发(concurrency)
要理解“并发”这个概念,必须得清楚,并发指的是程序的“结构”。当我们说这个程序是并发的,实际上,这句话应当表述成“这个程序采用了支持并发的设计”。好,既然并发指的是人为设计的结构,那么怎样的程序结构才叫做支持并发的设计?
正确的并发设计的标准是:使多个操作可以在重叠的时间段内进行(two tasks can start, run, and complete in overlapping time periods)。
这句话的重点有两个。我们先看“(操作)在重叠的时间段内进行”这个概念。它是否就是我们前面说到的并行呢?是,也不是。并行,当然是在重叠的时间段内执行,但是另外一种执行模式,也属于在重叠时间段内进行。这就是协程。
使用协程时,程序的执行看起来往往是这个样子:
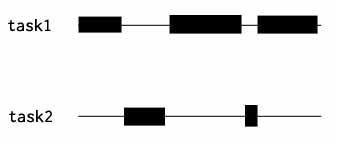
task1, task2 是两段不同的代码,比如两个函数,其中黑色块代表某段代码正在执行。注意,这里从始至终,在任何一个时间点上都只有一段代码在执行,但是,由于 task1 和 task2 在重叠的时间段内执行,所以这是一个支持并发的设计。与并行不同,单核单线程能支持并发。
经常看到这样一个说法,叫做并发执行。现在我们可以正确理解它。有两种可能:
- 原本想说的是“并行执行”,但是用错了词
- 指多个操作可以在重叠的时间段内进行,即,真的并行,或是类似上图那样的执行模式。
我的建议是尽可能不使用这个词,容易造成误会,尤其是对那些并发并行不分的人。但是读到这里的各位显然能正确区分,所以下面为了简便,将使用并发执行这个词。
第二个重点是“可以在重叠的时间段内进行”中的“可以”两个字。“可以”的意思是,正确的并发设计使并发执行成为可能,但是程序在实际运行时却不一定会出现多个任务执行时间段 overlap 的情形。比如:我们的程序会为每个任务开一个线程或者协程,只有一个任务时,显然不会出现多个任务执行时间段重叠的情况,有多个任务时,就会出现了。这里我们看到,并发并不描述程序执行的状态,它描述的是一种设计,是程序的结构,比如上面例子里“为每个任务开一个线程”的设计。并发设计和程序实际执行情况没有直接关联,但是正确的并发设计让并发执行成为可能。反之,如果程序被设计为执行完一个任务再接着执行下一个,那就不是并发设计了,因为做不到并发执行。
那么,如何实现支持并发的设计?两个字:拆分。
之所以并发设计往往需要把流程拆开,是因为如果不拆分也就不可能在同一时间段进行多个任务了。这种拆分可以是平行的拆分,比如抽象成同类的任务,也可以是不平行的,比如分为多个步骤。
并发和并行的关系
Different concurrent designs enable different ways to parallelize.
这句话来自著名的talk: Concurrency is not parallelism。它足够concise,以至于不需要过多解释。但是仅仅引用别人的话总是不太好,所以我再用之前文字的总结来说明:并发设计让并发执行成为可能,而并行是并发执行的一种模式。
最后,关于Concurrency is not parallelism这个talk再多说点。自从这个talk出来,直接引爆了一堆讨论并发vs并行的文章,并且无一例外提到这个talk,甚至有的文章直接用它的slide里的图片来说明。比如这张:
以为我要解释这张图吗?NO。放这张图的唯一原因就是萌萌的gopher。
再来张特写:

之前看到知乎上有个关于go为什么流行的问题,有个答案是“logo萌”当时我就笑喷了。
好像跑题了,继续说这个 talk。和很多人一样,我也是看了这个 talk 才开始思考 concurrency vs parallesim 的问题。为了研究那一堆推小车的 gopher 到底是怎么回事,我花费了相当多的时间。实际上后来我更多地是通过网上的只言片语(比如SO的回答)和自己的思考弄清了这个问题,talk 并没有很大帮助。彻底明白之后再回过头来看这个 talk,确实相当不错,Andrew Gerrand 对这个问题的理解绝对够深刻,但是太不新手向了。最大问题在于,那一堆 gopher 的例子不够好,太复杂。Andrew Gerrand 花了大把时间来讲述不同的并发设计,但是作为第一次接触这个话题的人,在没有搞清楚并发并行区别的情况下就去研究推小车的 gopher,太难了。“Different concurrent designs enable different ways to parallelize” 这句总结很精辟,但也只有那些已经透彻理解的人才能领会,比如我和看到这里的读者,对新手来说就和经文一样难懂。总结下来一句话,不要一开始就去看这个视频,也不要花时间研究推小车的gopher。Gopher is moe, but confusing.
2015.8.14 更新
事实上我之前的理解还是有错误。在《最近的几个面试》这篇文章里有提到。最近买了《七周七并发模型》这本书,发现其中有讲,在此摘录一下(英文版 p3~p4):
Although there’s a tendency to think that parallelism means multiple cores,
modern computers are parallel on many different levels. The reason why
individual cores have been able to get faster every year, until recently, is that
they’ve been using all those extra transistors predicted by Moore’s law in
parallel, both at the bit and at the instruction level.
Bit-Level Parallelism
Why is a 32-bit computer faster than an 8-bit one? Parallelism. If an 8-bit
computer wants to add two 32-bit numbers, it has to do it as a sequence of
8-bit operations. By contrast, a 32-bit computer can do it in one step, handling
each of the 4 bytes within the 32-bit numbers in parallel.
That’s why the history of computing has seen us move from 8- to 16-, 32-,
and now 64-bit architectures. The total amount of benefit we’ll see from this
kind of parallelism has its limits, though, which is why we’re unlikely to see
128-bit computers soon.
Instruction-Level Parallelism
Modern CPUs are highly parallel, using techniques like pipelining, out-of-order
execution, and speculative execution.
As programmers, we’ve mostly been able to ignore this because, despite the
fact that the processor has been doing things in parallel under our feet, it’s
carefully maintained the illusion that everything is happening sequentially.
This illusion is breaking down, however. Processor designers are no longer
able to find ways to increase the speed of an individual core. As we move into
a multicore world, we need to start worrying about the fact that instructions
aren’t handled sequentially. We’ll talk about this more in Memory Visibility,
on page ?.
Data Parallelism
Data-parallel (sometimes called SIMD, for “single instruction, multiple data”)
architectures are capable of performing the same operations on a large
quantity of data in parallel. They’re not suitable for every type of problem,
but they can be extremely effective in the right circumstances.
One of the applications that’s most amenable to data parallelism is image
processing. To increase the brightness of an image, for example, we increase
the brightness of each pixel. For this reason, modern GPUs (graphics processing
units) have evolved into extremely powerful data-parallel processors.
Task-Level Parallelism
Finally, we reach what most people think of as parallelism—multiple processors.
From a programmer’s point of view, the most important distinguishing
feature of a multiprocessor architecture is the memory model, specifically
whether it’s shared or distributed.
最关键的一点是,计算机在不同层次上都使用了并行技术。之前我讨论的实际上仅限于 Task-Level 这一层,在这一层上,并行无疑是并发的一个子集。但是并行并非并发的子集,因为在 Bit-Level 和 Instruction-Level 上的并行不属于并发——比如引文中举的 32 位计算机执行 32 位数加法的例子,同时处理 4 个字节显然是一种并行,但是它们都属于 32 位加法这一个任务,并不存在多个任务,也就根本没有并发。
所以,正确的说法是这样:
并行指物理上同时执行,并发指能够让多个任务在逻辑上交织执行的程序设计
按照我现在的理解,并发针对的是 Task-Level 及更高层,并行则不限。这也是它们的区别。
