今年是我开始认真对待投资的一年。几个月的实践下来,不谈具体操作,我意识到自己的整体思路有一些问题。因此用这篇文章总结一下。
我主要的问题是太过追求找到高 beta 的标的,却忽视了那些领头羊公司。比如,我今年从未投资过 Nvidia 和 Palantir,甚至从未把它们放进观察列表。很不可思议吧。即便我知道这波反弹它们肯定会涨,但却始终不肯看它们一眼。几个月下来,它们涨得并不比那些动辄一天 10% 20% 的小票少,波动却小得多。我花很多时间看各种小票,最后反而因为判断错误没有很好地利用资金,经常直接就止损了。
往后,我打算这样分配资金:
60% 投入 3 - 4 家高确定性、高成长的领头羊公司,持仓数月 - 数年:
- 如果重来一次,这一波我会选择 NVDA、VST、PLTR、HOOD,各15%
30% 投入 1 - 2 家短期内的热点题材,持仓数周:
- 过去几个月的热门题材有核能、航天、稀土、量子计算等,并不难找。
10% 投入当前炒作的 1 支妖股,持仓数天(当前没有就不买):
至于为什么不买标普500和纳斯达克100,因为 401k 里已经买了,所以主动投资就没必要重复。
这样分配的好处有几点:
- 提高了资金的利用率,避免持有太多现金(我的现金已经放在股票账户之外了)
- 缩小选股范围:买一个标的前先问自己:是龙头吗?是热点题材吗?正在被炒作吗?这样一下就能删掉 90% 的股票
- 节省时间——我不用再去每天找各种机会,只要热点来了买入即可
- 省心——由于领头羊股票占比 60%,降低了仓位的整体波动
当然,短期内美股已经太高,我目前不会上太大仓位。等之后有机会就开始实践。
之后可能会在博客里写一些投资相关的文章。先从这篇开始,我想列举几个初入投资容易犯的错误,其中的坑我也踩过。
选错了市场
正如游戏里不会让你一上来就挑战最终 boss,初入投资最好不要挑战高难度市场。这里不得不提的就是A股,一个典型的地狱难度市场,具体可参考《为什么A股是价值投资者的坟墓?》。
我当然不是说投A股一定亏钱,或者投美股一定赚钱(少部分人在A股赚钱或许更容易)。关键在于,如果处在一个不正常的市场,你将无法通过反馈机制纠正错误并逐渐成长(关于「反馈」,我未来还会写文章)。比如,我看到不少人抱着赚钱致富的心态进入A股,很快便遭受打击退出了市场,并从此认定「投资都是骗钱的玩意,不投资就是最好的投资」。选错市场,会让人对投资这件事本身失去信心,而这是最可怕的一点。
一开始就投入大量资金
这可能是新手最常犯的错误,包括我自己。
除了极少数天赋异禀的选手,基本上人们刚开始投资时都会亏钱,不论身处哪个市场。其中原理也很简单:大部分人开始投资,都是因为市场或者某个标的已经热到不能再热了。当身边的人都在赚钱却只有你被落下,你能不急吗?当年的牛顿就是这样:
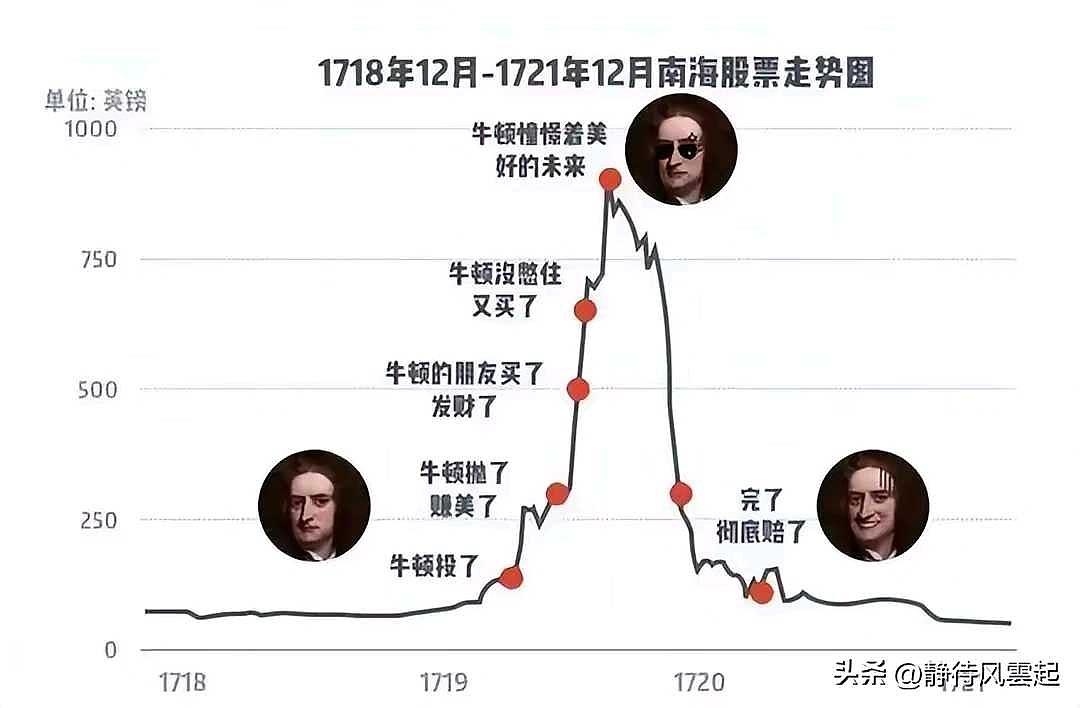
结果呢?你入市的时候已经是牛市末期。很快,这支股票或者市场就崩盘了。
既然开始时亏钱是自然规律,与其违抗它,不如想办法减小损失。后面会说怎么做。
在各种投资风格之间横跳
提到「投资交易」,有人会说不就是低买高卖吗?然而这种过度简化是有害的,因为它忽略了投资交易有的不同风格,且它们之间的差异极大,甚至完全相反。比如,我们最常听到的「价值投资」流派,要求投资者花费大量时间去彻底搞懂一家公司,而超短线日内交易往往不在乎基本面。你可以做多或者做空,左侧交易或者右侧交易,买入或者卖出各种期权;你可以买大盘、行业 ETF、个股,甚至加密货币,等等等等,不一而足。
在任意一个时间点,所有选项对投资者来说都是开放的。选项多固然好,却也让投资者陷入了选择困难症。同时,社交媒体上一会是这个人买A的期权翻了十倍,一会是这个人投资B五天翻倍。这些选项和声音会让新手们无比迷茫和焦虑,于是开始浏览大量的消息,生怕错过什么投资机会。看到好消息便马上买入,听闻负面消息便马上做空,要么就是跟单各种大V和「老师」。长此以往,不论赚钱与否,他们生活都将被市场裹挟,惶惶不可终日。
我很喜欢 Dawei 在《Ep 53. AI 能否帮我们做出更好的投资决策? - 捕蛇者说》里的观点:「如果投资不能让我们的生活变得更好,那它就没有意义」。我认为,不让自己被市场裹挟的核心在于确立自己的交易风格。每种交易模式都有优缺点,但相同点在于都可以赚钱。这就和编程语言一样,你既不可能,也没有必要精通所有的编程语言。反之,你的上限取决于你最擅长的那种交易模式(编程语言)。人的时间是有限的,必须要减小决策的解空间。这样不仅可以提高决策效率,更可以专注于精进特定的交易模式。
那么,如何开始?
这个问题没有标准答案,但我想给点框架性的建议。
Step 1. 假设你手头有 10w 块钱想投资。你要做的第一件事,就是把这部分钱除以十,也就是拿出一万去投资,把剩下的九万放在银行里。这样即便你亏了一半,也就是五千块而已,并不伤筋动骨。
Step 2. 花费三到六个月,随心所欲且尽可能多地尝试各种投资方法。这里的关注点不在于每种方法是否能赚钱,而在于仔细体察自己对于每种操作的感受,如有需要可以记录下来。举几个例子:
- 个股亏了 10%,我当时的心情是怎样的,是否可以平静地止损?
- 期权归零了,我是否想自杀?
- 买标普500 一个月涨了 2%,我是否嫌涨得太慢?
这样,你将建立一个量表,去量化自己对每一种投资方式的适应程度。而适应程度,决定了你未来应该采取的投资方式。只有当投资方式符合自己性格的时候,你才真正有可能把它执行好。相信我,没有人在实践之前真正了解自己。你自以为的了解,多半是幻觉。
Step 3. 当你找到了自己最舒服的 1-2 种投资模式,把它们固定下来,在往后的若干年里不再考虑其它的投资方式。同时,找到讲解这种特定投资模式的书,研读它们。就这样开始吧。重复地练习加上前人的经验,一定会让你进步飞快。
我自己也是新手,还在学习的路上,本文也算是阶段性总结,希望对你有帮助。限于篇幅,很多地方只能点到为止,之后想到了再展开写。
创造回忆
不少动漫里都有主角团去海边这种老掉牙的桥段,而漫画家常借人物之口说出此行的目的是“创造美好回忆”。这里有意思的点在于,相对于参与海边之行和学园祭带来的快乐,漫画家们强调的却是“回忆”,这种在事后看才有价值的东西。由于中日间的文化差异,中国人对“创造回忆”这个概念并不熟悉。也有可能是“玫瑰色”的日本高中生活实在是太过美好,反衬出成为社畜之后的苦逼;而在中国,即便进入社会再怎么苦,恐怕都比不上高中时期。
我自认为非常幸运,可以在学生时期留下了一些美好的片段。进入社会之后,在我内心充满失落、煎熬和焦虑的时刻,我发现能带给我最大慰藉和力量的总是那些过往的美好回忆。这让我逐渐意识到回忆的力量,也开始理解为什么漫画里总强调“创造回忆”而不是“创造体验”——体验转瞬即逝,而回忆则随着时间的陈酿愈发珍贵。我相信一个人美好的回忆(尤其是青少年时期)越多,他的精神内核也就越稳定。令人遗憾的是,不幸的家庭和青少年经历同样将伴随人的一生,它不仅让人无法从过往汲取力量,更会带来持久的伤痛。
记忆股息
《DIE WITH ZERO》这本书提倡在死前花完你所有的钱。为了解释花钱的目的,作者自创了一个概念叫『记忆股息(Memory Dividend)』。这个概念让我醍醐灌顶,因为它准确而优美地阐述了我之前脑中模糊的感觉。下面我将会做个简单介绍。
首先,作者提到你可以把人生体验数值化。简单来说,就是给自己从体验中感受到的快乐打分。这样积累下来,就会有一个每年的分数。每个人对同一件事的感受大不相同,因此这个分数是完全主观的。
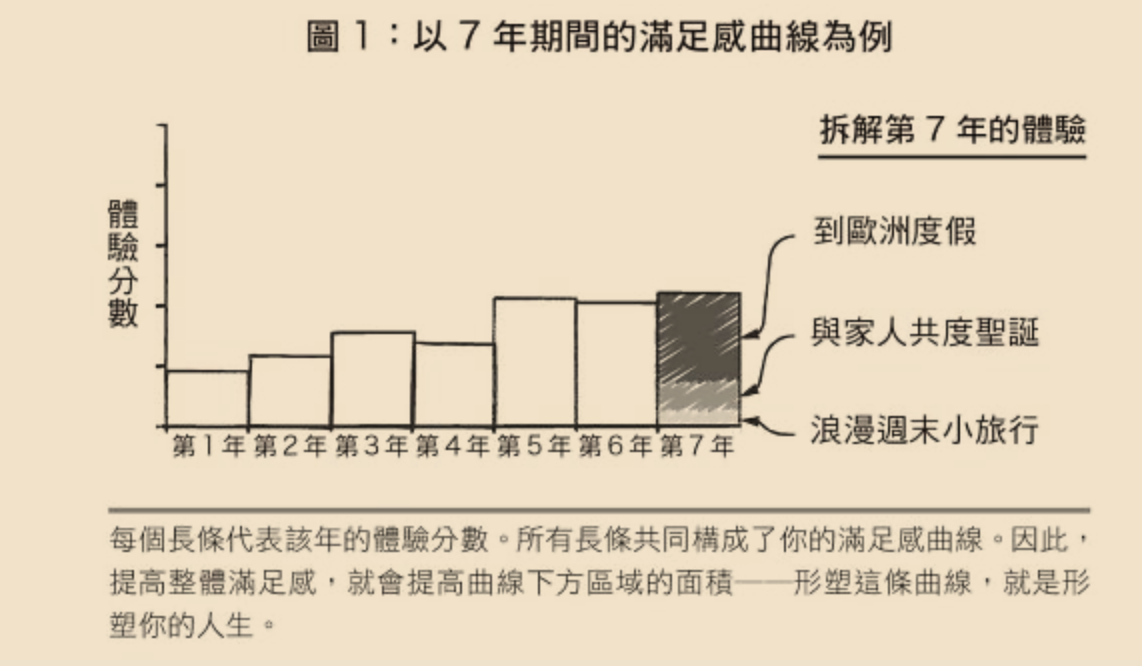
然后便可以引入『记忆股息』概念。股息是给股东定期派发的分红,即便股价不变,股息也能帮你积累财富。作者认为记忆带来的满足感亦是如此——已经获得的快乐记忆,将随着时间推移持续带给你满足感。经过的时间越久,这些积累起来的满足感也就越大。因此可以知道,即便是同样的体验,越早获得收益也就越大。
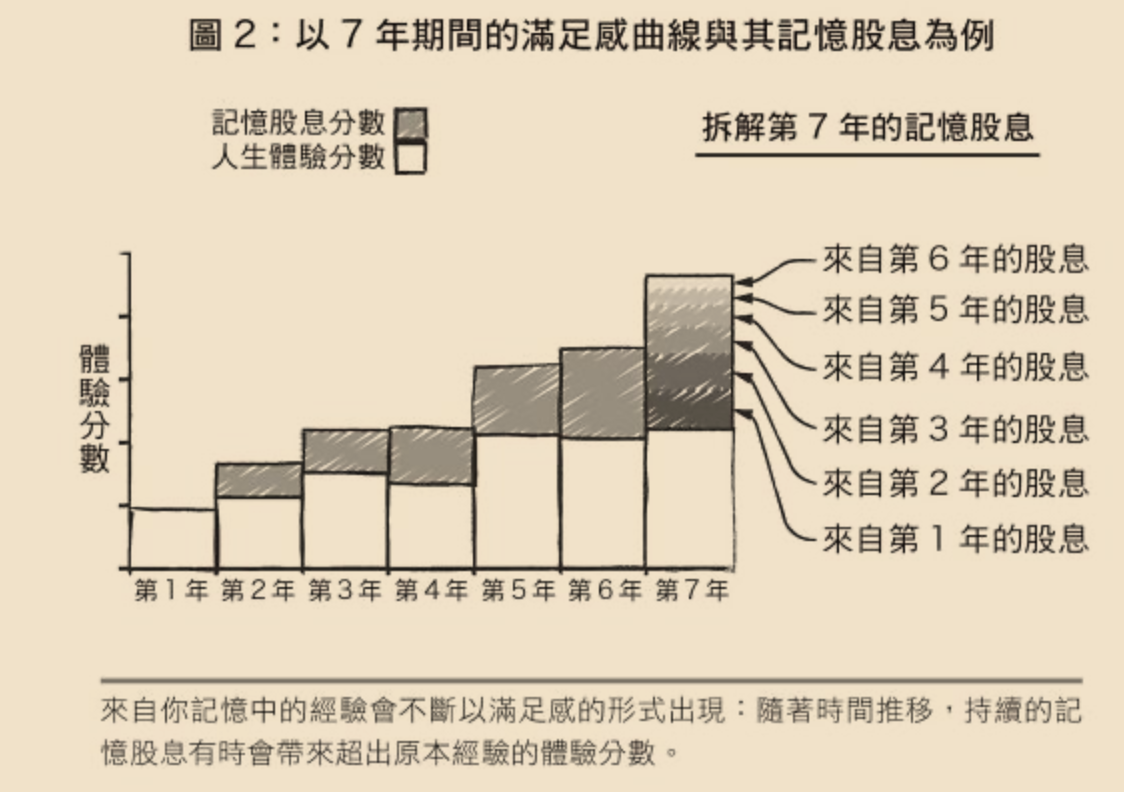
作者还提到你应该选择自己要去经历的体验,这点我也非常赞同。以我个人为例,“创造”带来的快乐无与伦比,而买奢侈品则微乎其微,因此我会希望最大化创造的体验。然而另一方面,我们虽看似有选择的自由,却往往沿着某种规划好的轨道,依靠惯性在生活。我们都说“身不由己”,现在先攒钱,等退休了再享受。然而根据记忆股息理论,等退休了再去获得美好回忆,即便可以做到,留给你积累股息的时间也已所剩不多。说到底,在人生的最后,你拥有的只有回忆,是它决定了你对这一生是否满意。
人生体验
有句话叫『人生就是所有体验的总和』,记忆股息也无非是这句话的另一种表述。我听过一个有趣的理论:为什么世间诞生了生命和意识,因为造物主(根据你的信仰它可以是不同的东西,也可以就是宇宙本身)希望以不同的身份去经历和体验一切事物。我喜欢这个理论,不是因为它有多科学,而是因为它很浪漫。以及,万一真是如此呢?
最后再推荐一期播客《你一生的财富 - 知行小酒馆》。我想,体验也应该被纳入人生的财富列表,甚至应该排行首位——因为健康、金钱、社交等等,说到底不都是为了获得更好的人生体验吗?
